玛德!从今天开始补基础,谁都别拦我 👴要成为带手子
4.20日更新
今日任务:滴水逆向+小黄书更新
好的👴回来了,出去🚶♂️了一会,开始学习:
-
基于缓冲区溢出的HelloWorld
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void HelloWord()
{
printf("Hello World");
getchar();
}
void Fun()
{
int arr[5] = {1,2,3,4,5};
arr[6] = (int)HelloWord;
}
int main()
{
Fun();
return 0;
}
🙃直接去测试看看什么妖魔鬼怪
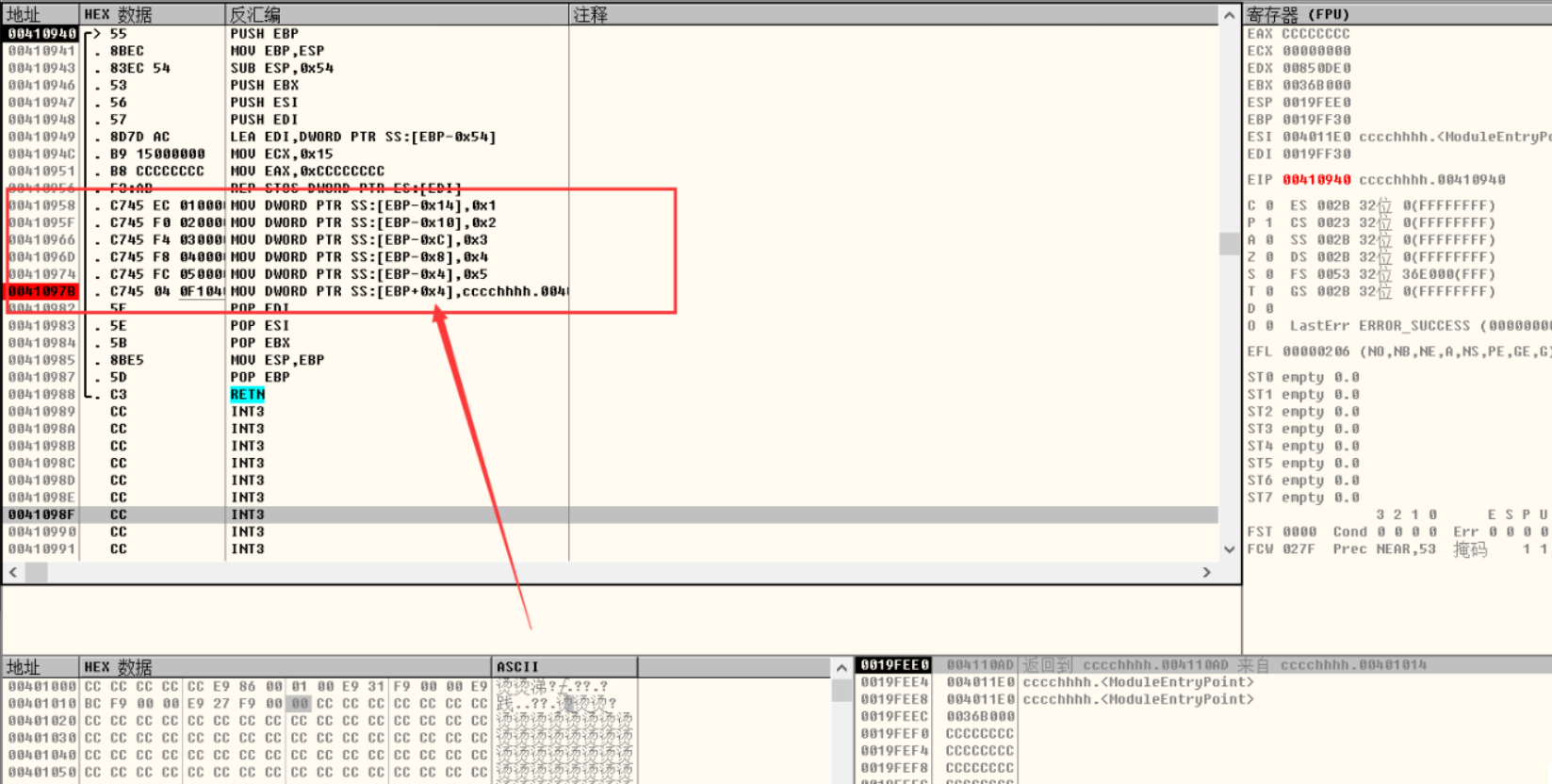
压入栈后,发现将arr[6] = (int)HelloWord这句话压入了ebp+0x4,一般我们程序的ebp+0x4是我们返回的地址在pop eip的ret的位置,所以ret的位置把堆栈的位置弹出到eip改变了所以会返回另一个调用函数的东西
👴去更深究了一波一个指令

发现 int arr = (int)HelloWord与int arr = (int)&HelloWord干的事情是一样的,把helloword的地址放到arr中后面进行一个调用
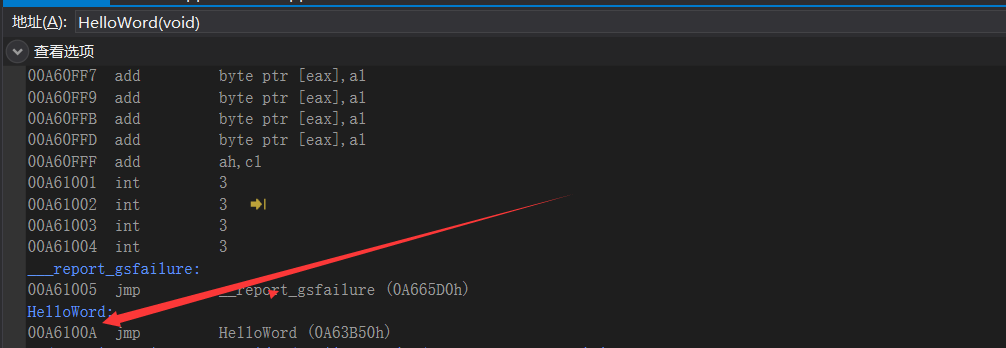
给👴过去!
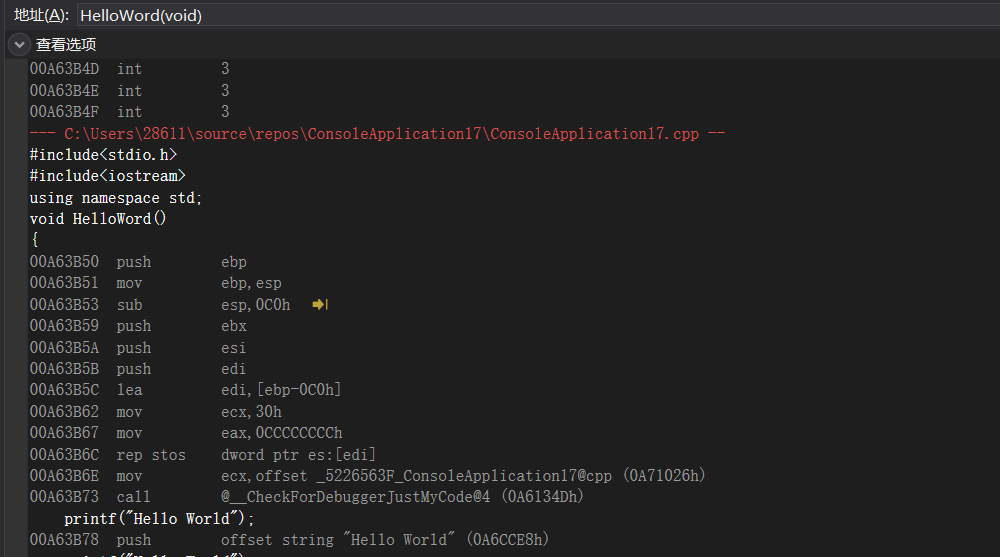
给自己加个🍗,就是这个逻辑下一个!
-
永不停止的HelloWorld
1
2
3
4
5
6
7
8
9
10
11void Fun()
{
int i;
int arr[5] = {0};
for(i=0;i<=5;i++)
{
arr[i] = 0;
printf("Hello World!\n");
}
}
好的🙃继续看看什么操作,简单分析一下就是i=5的时候arr数组已经溢出
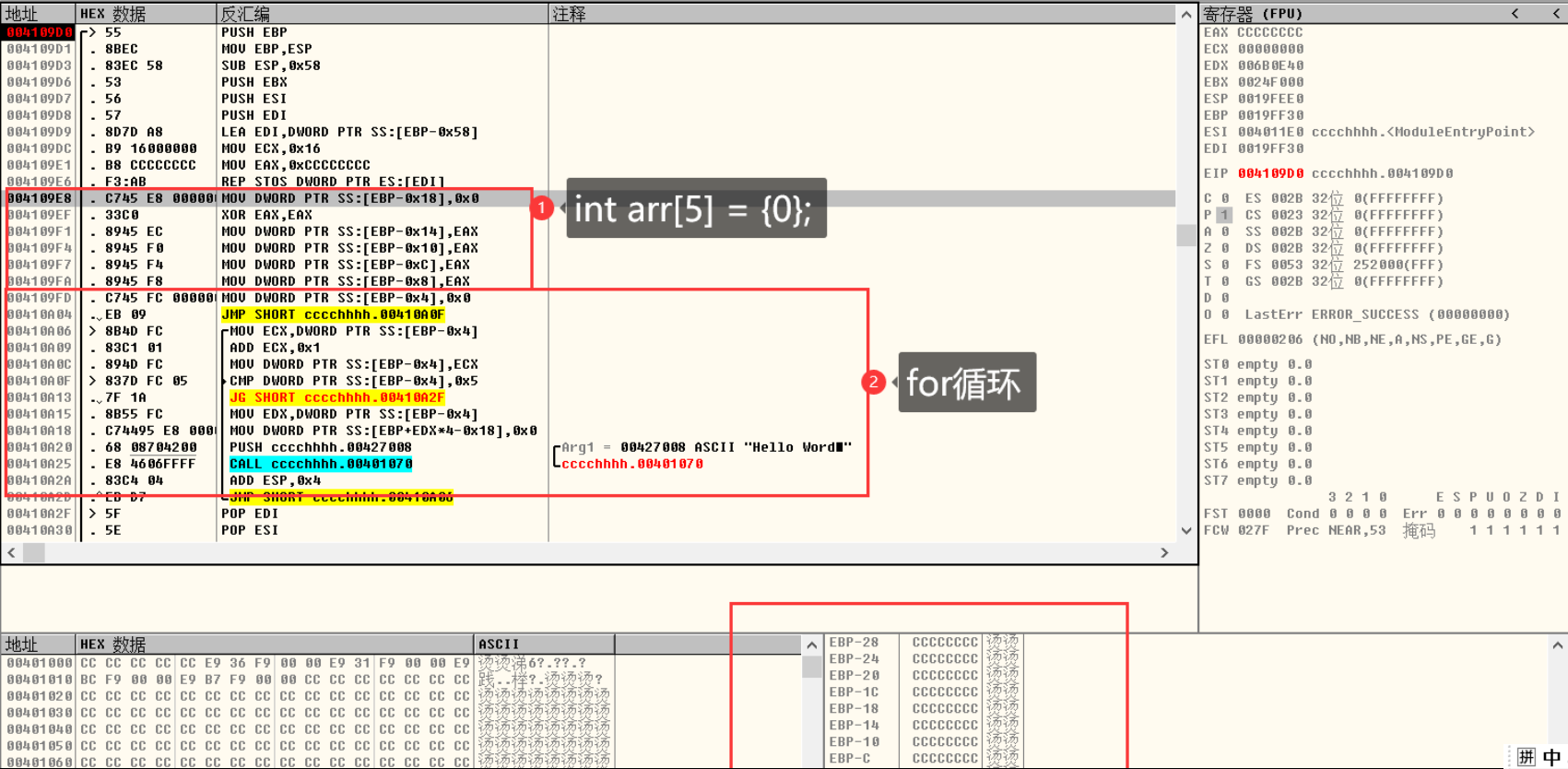
好的 我们可以看到,我们的arr[i]进行了一个奇妙的操作,把5个成员放入堆栈后,因为i是局部变量在ebp-0x4中也就是我们将要溢出的arr[5]中,在下面一次给arr[i]变成0且ebp-0x4中的值+1的操作中发现,在最后一次[ebp+0x5*0x4-0x18] = [ebp-0x4] 👴笑了!于是无限循环
在这两个实验中,我可以发现,嗯!编译器牛逼!反正这几个代码是错的,我编译器大人就给你优化的天下无敌好吧,这里想给他们一🔪,坑害了多少人不调试的坏毛病!😡
步入正题好吧!
变量
变量声明就是👴要告诉计算机👴要用一块内存,用多少内存是由数据类型决定int i;【宽度,作用域,种类】作用域:在函数外是全局变量,在程序变成.exe的时候,💻大大会给你分配一块特定的内存,如果在函数里面,是不给你分的,什么时候用,人家再给你分

给👴仔细看,这里是一个3给了一个特定的地址,用这个来分辨全局变量,通过dword和word来分辨是什么类型

看到不同了吧!一个全局一个局部,局部变量正常是没有内存的,嗯哼👌
全局变量如果没有赋给初值就是0,局部如果不给就是CC因为他在缓冲区的啦!😡小爷给自己测试一下,好的,👴的编译器TQL,又给优化了!你妹的!好的直接说,一般就是CCCC毕竟局部变量在ebp-0x4的位置
类型转换
👴不废话 直接上手,了解一下movsx与movzx


movsx是看到al是8位,cx是16位,那么强转,是看符号位的,如果单独拿一个mov al,0xFF来,👴想给他看成有符号就有符号,不想就不想

movzx是不看符号位直接补0
我们在c语言写代码的时候如果我们没有指明默认都是有符号的

movsx告诉了我们我们默认都是有符号的:char —— byte short —— word int——dword
我现在换成无符号的(unsigned)试一下
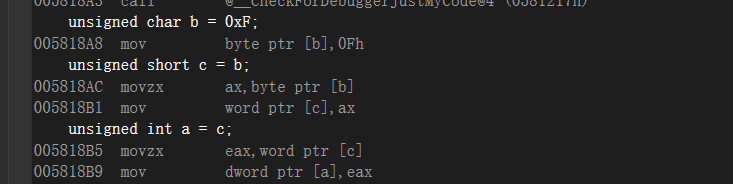
好的是movzx 👴了解了,汇编真好玩👍 补充:小的往大的放是填充,大的往小的放是截取

👴这么笨都懂了,估计都能懂
表达式
1 | void FUN(int a, int b) { |
表达式看到了,没有变量存储这个表达式的值,👴看看干什么了
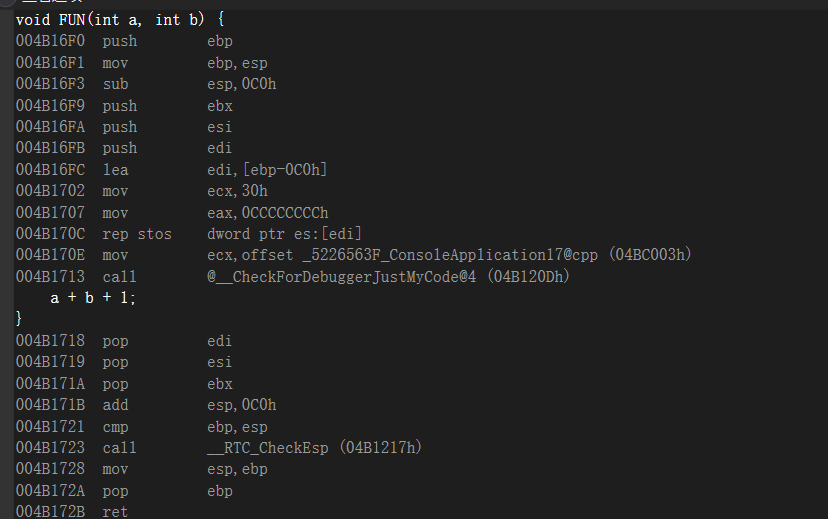
好的,啥也没干,void fun();啥样他啥样👍,所以酱样子是不对的,所以编译通过但是不生成代码,需要与赋值或者其他控制语句一起组合时候才可以,😡有人会问表达式如果数据类型不一样怎么办,👴再去试一下
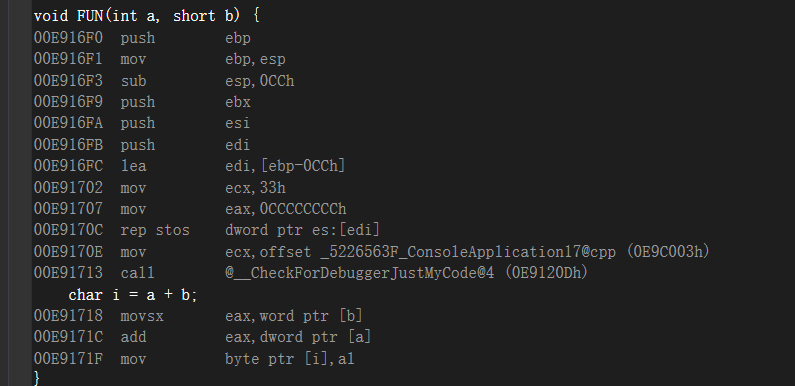
看到了吧,把b强转位a的类型但是最后跟的 i 的数据类型走的,如果表达式中变量存在无符号数的时候,最后本身的结构会变成无符号数
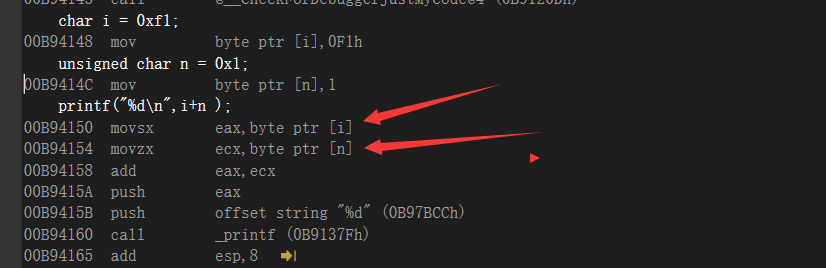
👵直接丢例子给老子懂!😡这里本可爱最脑瘫瘫的地方就是unsigned int i =0xffffffff我去进行 %d ,结果是-1,😡真够脑瘫的,人家本来符号位就是1 1111111%d就是4位且有符号输出,变成%u就是4294967295!不需要什么movsx和movzx的操作!真的是笨笨笨!😭
自己总结:
正常我们进行强转类型的时候,如果不是unsigned那么就是movsx如果是的话就是movzx,有符号和无符号相加结果是计算机到时候怎么看都可以
表达式与语句
影响cpu或者影响了内存的分配我们称为语句,后面要有一个分号才可以称为语句
1 | int FUN(int a, short b) { |
这里👴提一嘴 函数调用的返回,一般我们程序执行完堆栈的分配的空间都变成了垃圾数据,但是我程序return一个i,我直接把i的值返回给eax
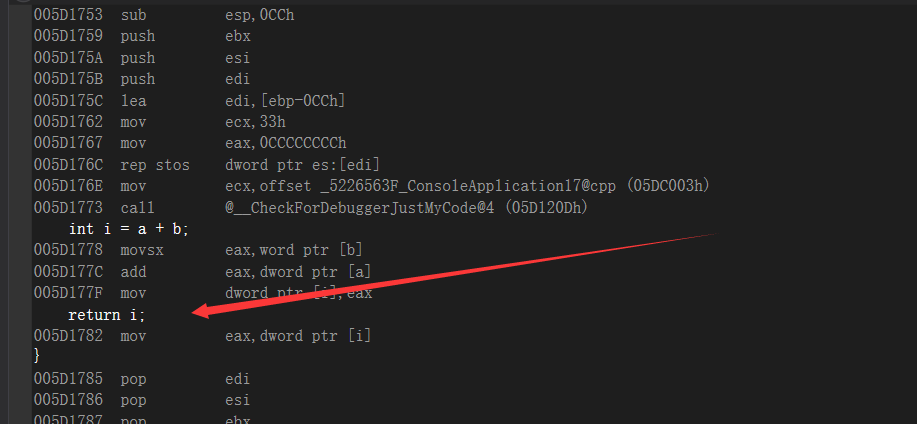
这里看一下 int a = b == c;的功能
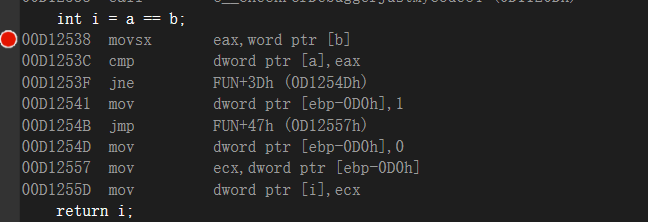
如果不相等就跳转到0xD1254D,如果相等就不跳转:等同于
1 | xor ecx,ecx |
sete cl这两个值如果一样的话就会把cx的值设置成1,如果不相等就不sete,也有个(setne)
开始小黄书:
OD基本使用
| 快捷键 | 功能说明 |
|---|---|
| F2 | 断点 |
| F3 | 加载一个可执行程序,进行分析 |
| F4 | 程序执行到光标处 |
| F7 | 单步步入 |
| F8 | 单步步过 |
| F9 | 直接运行程序,遇见断点处停止 |
| Ctrl+F2 | 重新运行程序到起始位置 |
| Ctrl+F9 | 执行函数到返回处,用于跳出函数实现 |
| Alt+F9 | 执行到用户代码处,用于快速跳出系统函数 |
| Ctrl+G | 定位地址 |
IDA基本使用
| 快捷键 | 功能说明 |
|---|---|
| Enter | 跟进函数实现 |
| Esc | 返回跟进位置 |
| A | 解释光标处的地址为一个字符串的首地址 |
| B | 十六进制转化为二进制 |
| C | 解释光标处地址为一条指令 |
| D | 解释该地址为数据 |
| G | 查找地址 |
| H | 十六进制转化成十进制 |
| K | 数据解释为栈变量 |
| : | 注释 |
| M | 解释为枚举成员 |
| N | 重命名 |
| O | 字符串标号 |
| T | 解释为结构体成员 |
| X | 转化视图为交叉参考模式 |
| Shift+F9 | 添加结构体 |
👴第一次看到这么多快捷键学到了
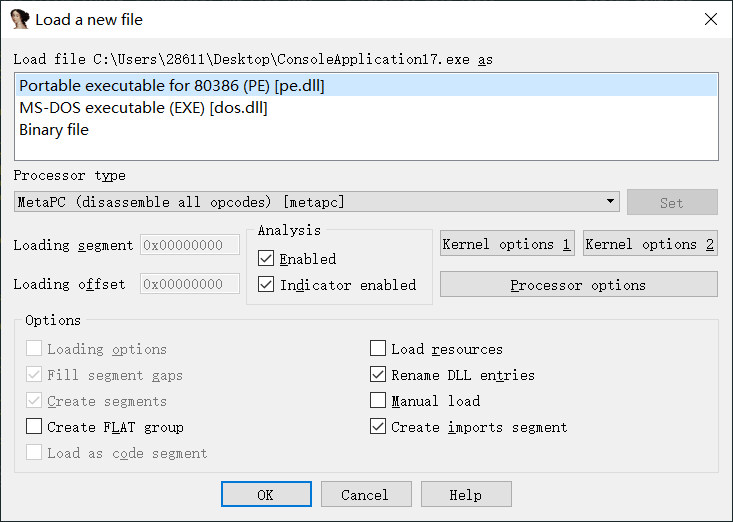
三个选项
1.分析文件为一个PE格式的文件
2.分析文件为一个DOS控制台下的一个文件
3.分析文件为一个二进制的文件
sig:
这里👴大概说一下这个sig:
我们一般IDA可以识别函数的MessageBoxA等等参数信息,是因为IDA通过SIG文件来识别的,所以在安装的时候我们会有相应的.sig在pc那个文件夹下面了,所以我们可以利用这个,来去识别第三方的库函数,简化分析
SIG制作流程:
创建模式文件 pcf.exe xxx.lib xxx.pat
创建签名文件 sigmake.exe xxx.pat xxx.sig
直接举书上的例子好吧!
1 | void ShowSig(){ |
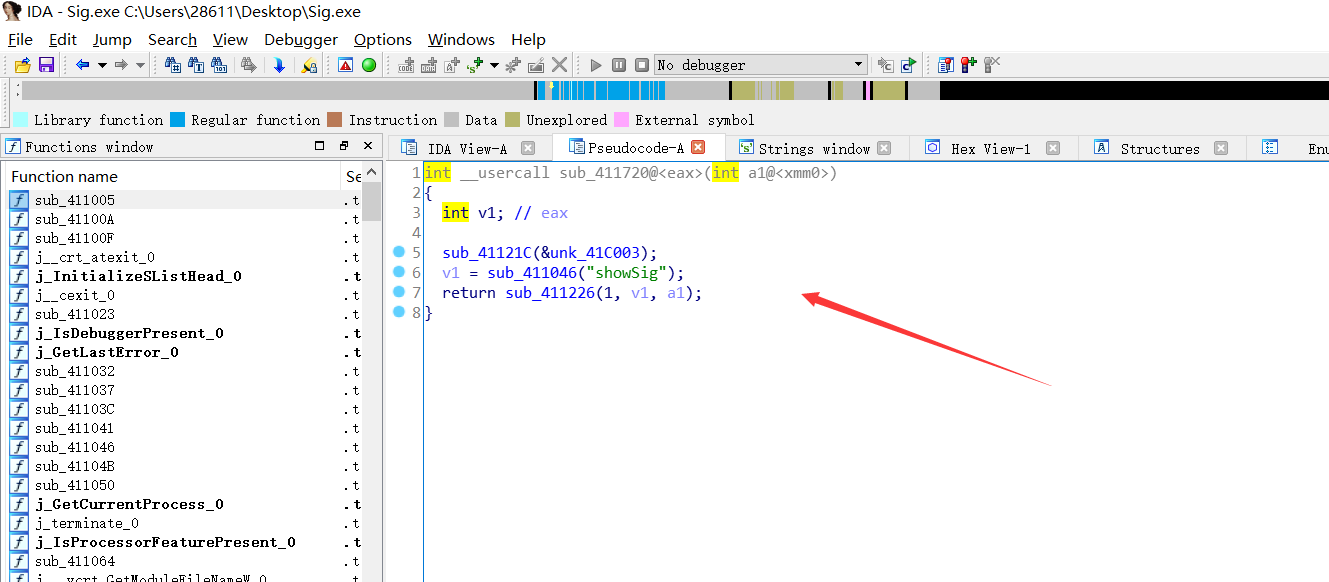
没有加载sig之前,那么我们制作一下

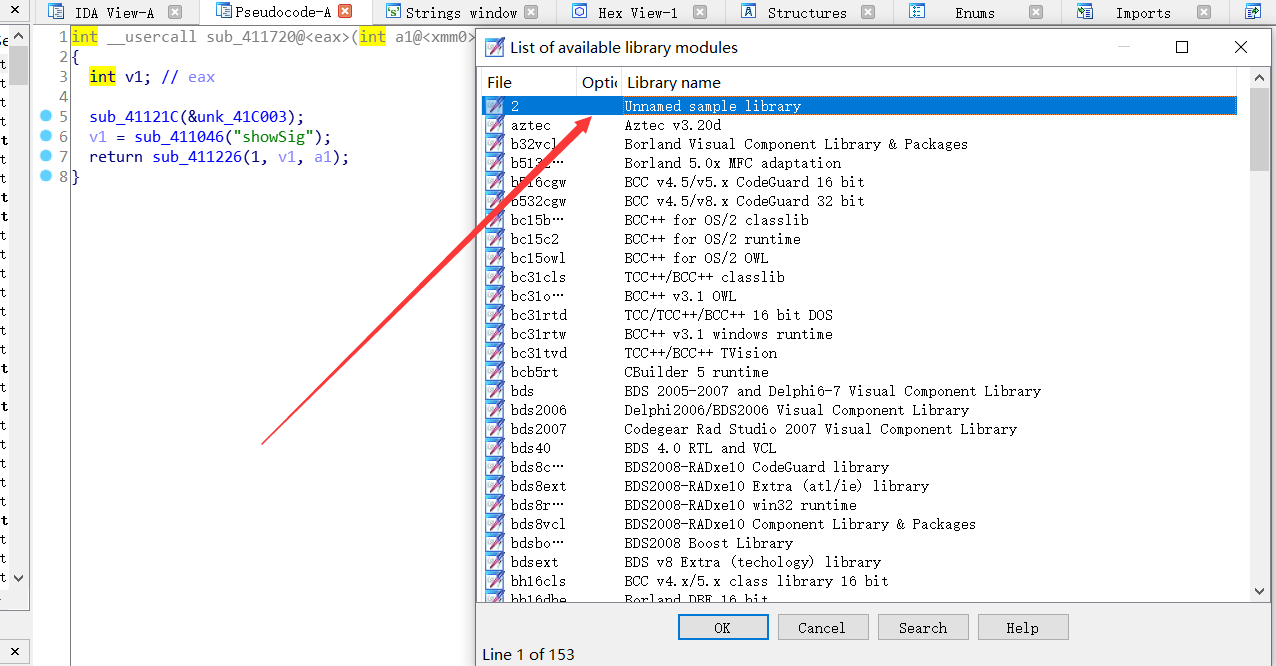
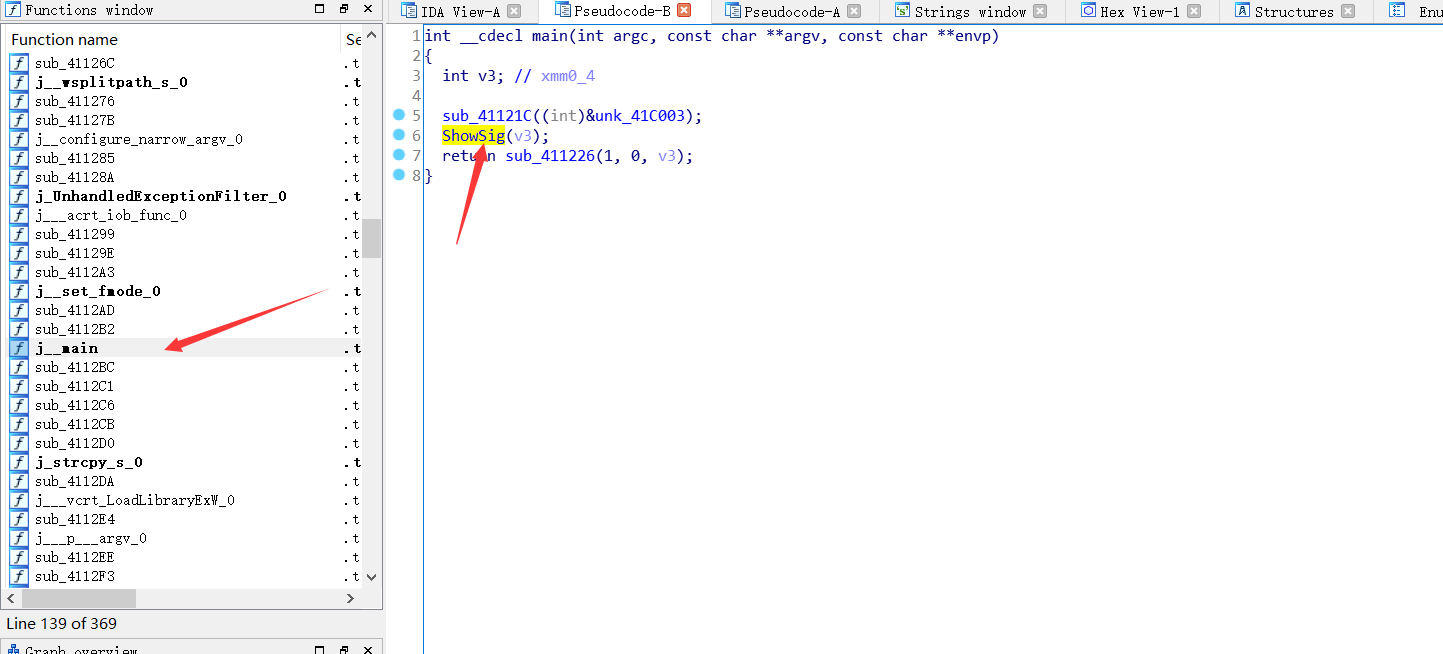
可以看到恢复了符号表,真香🍔,👴感觉书上说的复杂了点,直接我们在ida中有
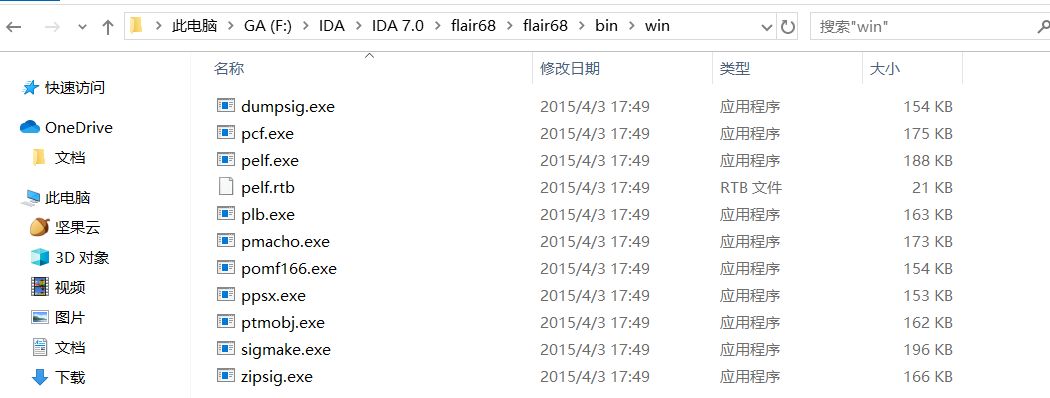
打开powershell,搞就完事,然后把生成的.sig丢到 sig文件下的pc文件夹即可,👴睡了 晚安
4.21日更新
👴迷迷糊糊睡到了下午1.27,感觉脑袋😴的,不说这么多,™的学习
今日任务:滴水逆向+小黄书更新+(看雪CTF第三题研究:不知道能研究多少😡)
步入正题!
循环
do while循环和while 循环就不用👴说了吧,还有个循环是for循环,for(表达式1;表达式2;表达式3){//执行代码4}第一次执行为1 2 4 3,第二次为2 4 3…到最后一次2不满足了退出
👴这里举一个好玩的for的例子假设:
1 | for(;;){ |
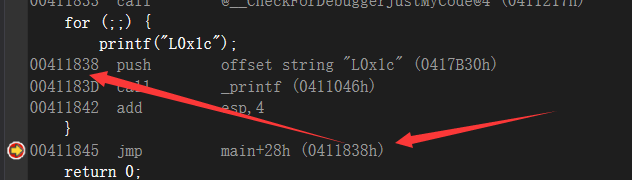
看到了吗,这里是无限执行的,所以假设这里如果什么都不写,这里表达式2的位置的地方是永真的
👴在这里看到了个好玩的就是,不用第三个值来完成两个值交换(目测是数学问题,反正记录一下嘛😁)
1 | int x=2; |
这里只能说数学牛逼!👍
其实一个函数可以有多个return,但是多个return里面只进行了一个
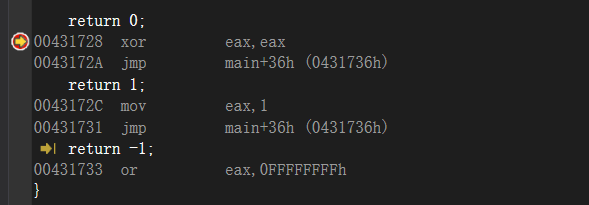
于是👴去网上看了一下return 0 return 1 return -1的作用
- return 0:一般用在主函数结束时,按照程序开发的一般惯例,表示成功完成本函数
- return -1 :表示返回一个代数值,一般用在子函数结尾。按照程序开发的一般惯例,表示该函数失败
布尔类型时候:
- return 0:返回假
- return 1:返回真
我进行了一个猜想,我在想return 2 3 4可以吗,干什么的,我去vs试一下吧看一下汇编做了什么
大概清楚,跟正常返回一样,给eax值,然后让别人到时候调用eax返回值用的
大概听了海哥的两节课,👴感觉他讲了很多的正向知识,大概自己都了解,我这里就不记录了,直接自己搞一下简简单单的冒泡排序的正向写法吧
1 | while(m<length-1){ |
开始小黄书:
反汇编引擎的工作原理
👴第一次了解准备好好学一手
X86平台下使用的汇编指令对应的二进制机器码是Intel指令集——Opcode
| Prefix | code | Mode R/M | SIB Displacement | Immediate |
|---|---|---|---|---|
| 指令前缀 | 指令操作码 | 操作数类型 | 辅助Mode R/M,计算地址偏移 | 立即数 |
Opcode这里书上没有给太多解释,我直接在CSDN找到了一篇文章,说的挺不错的,这里自己总结一下(网址:https://blog.csdn.net/kl195375/article/details/89788837)
我们的计算机只认识0与1是没毛病的,但是我们写的源程序并不是0与1,那么计算机如何知道我们程序的含义?👴现在就来学习一下!
好的!我从CSDN学完🏃♂️回来了!
假设我们写一个汇编的NOP,我们在编译的时候,汇编语言会扫描整个源代码,所以我们知道计算机只认识0与1,那么源代码NOP无法运行,所以为了让计算机生成能运行的东西,我们要用0x90来代替
这里的0x90是我们说的Opcode,而Nop是我们说的助记符(menemonic)
可是一个Opcode对应一个menemonic吗
| Opcode | mnemonic |
|---|---|
| 0x90 | NOP |
| 0x90 | XCHG AX,AX |
| 0x90 | XCHG EAX,EAX |
那么一个mnemonic对应一个Opcode吗
| menemonic | Opcode |
|---|---|
| ADD EAX, 1 | 0x83C001 |
| ADD EAX, 1 | 0x0501000000 |
| ADD EAX, 1 | 0x81C001000000 |
所以:一个OpCode 不只对应一个menemonic ,一个menemonic不只对应一个OpCode ,其实这里👴有个疑问,就是为什么是一对多的情况,有点八太懂,这里我一会查阅一下资料!就回来补充😭
上面说的那个Opcode的6个域排列顺序,是不可以改变的,一般来说最不可少的就是code这个域
| OpCode | menemonic |
|---|---|
| 0xC3 | RETN |
| 0x2F | DAS |
| 0x90 | NOP |
| 0xAC | LODSB |
假设这几个Opcode都只用到了code这一项,那么我们拿出0xAC这个code,我们做个测试
0xAC ------- 0xF3AC:REP LODSB,大概我们会猜到改变是因为F3的添加(Prefixes)的问题
1 | AC |
这里说一下他们的顺序不可以变举个例子:
| OpCode | menemonic |
|---|---|
| 4004 | INC EAX |
| 0440 | ADD AL, 40h |
-
Prefix:指令前缀,作为指令的补助
- 重复指令:如REP,REPE
- 跨段指令:如MOV DWORD PTR FS:[xxxxx],0
- 将操作数从32位转为16位:如MOV AX,WORD PTR DS:[EAX]
- 将地址从16位转为32位:如MOV EAX,DWORD PTR DS:[BX+SI]
-
code:指令操作码,有时候还需要Mode R/M , SIB , Displacement帮助,才可以完善信息
-
Mode R/M:操作数类型:用来辅助menemonic后的操作数类型,R寄存器,M内存单元,6 7位的4种可能,用来描述,0 1 2位是寄存器还是内存单元,以及3中寻址方式
7 6 5 4 3 2 1 0 指定寄存器及寻址方式 寄存器/Opcode 寄存器/内存单元 -
SIB:辅助Mode R/M,计算地址偏移,SIB寻址方式就是基址+变址,
MOV EAX,DWORD PTR DS:[EBX+ECX*2]其中ECX和2都是SIB来制定的,这里的指定乘数,只有4种可能:1 2 4 8
7 6 5 4 3 2 1 0 指定乘数 指定变址寄存器 指定基质寄存器 -
Displacement:辅助Mode R/M,计算地址偏移,比如
MOV EAX,DWORD PTR DS:[EBX+ECX*2+3],其中+3是由Displacement决定的 -
Immediate:立即数,用于解释语句中操作数为常量的情况
反汇编引擎Proview源码片段
给出汇编:👍这里🐶十月还是有点作用的 给了pdf
1 | //机器码解析函数 |
刚把柴佬的任务完成,急忙🏃♂️回来,继续整理笔记😁
代码省略了其他机器码的解析过程,列举了push的两种机器指令方式,自己大概了解了:通过解析Opcode指令操作码,找到对应的解析方式,将机器码重组为汇编代码。通过第一个参数DISASSEMBLY *Disasm传出解析结果,将机器码指令长度由参数Index传出,用于寻找下一个Opcode指令操作码
Decode对机器码进行分析
1 | //假设此字符数组为机器指令编码 |
通过函数Decode2Asm,启动反汇编引擎Proview,解析出对应汇编指令语句代码,并输出
Decode2Asm实现流程
1 | void_stdcall |
对汇编引擎Proview的使用进行了封装,以简化Decode函数的调用过程,方便使用者调用
👌后面看了3页讲的是整数类型,有符号和无符号,以及浮点数类型,大该了解不是很难,笔记不用写!👴就是这么嚣张!
小插曲:柴佬的作业
😁受到柴佬的拜托,帮忙完成一个作业,👴义不容辞
看到是个crackme:
od打开好吧
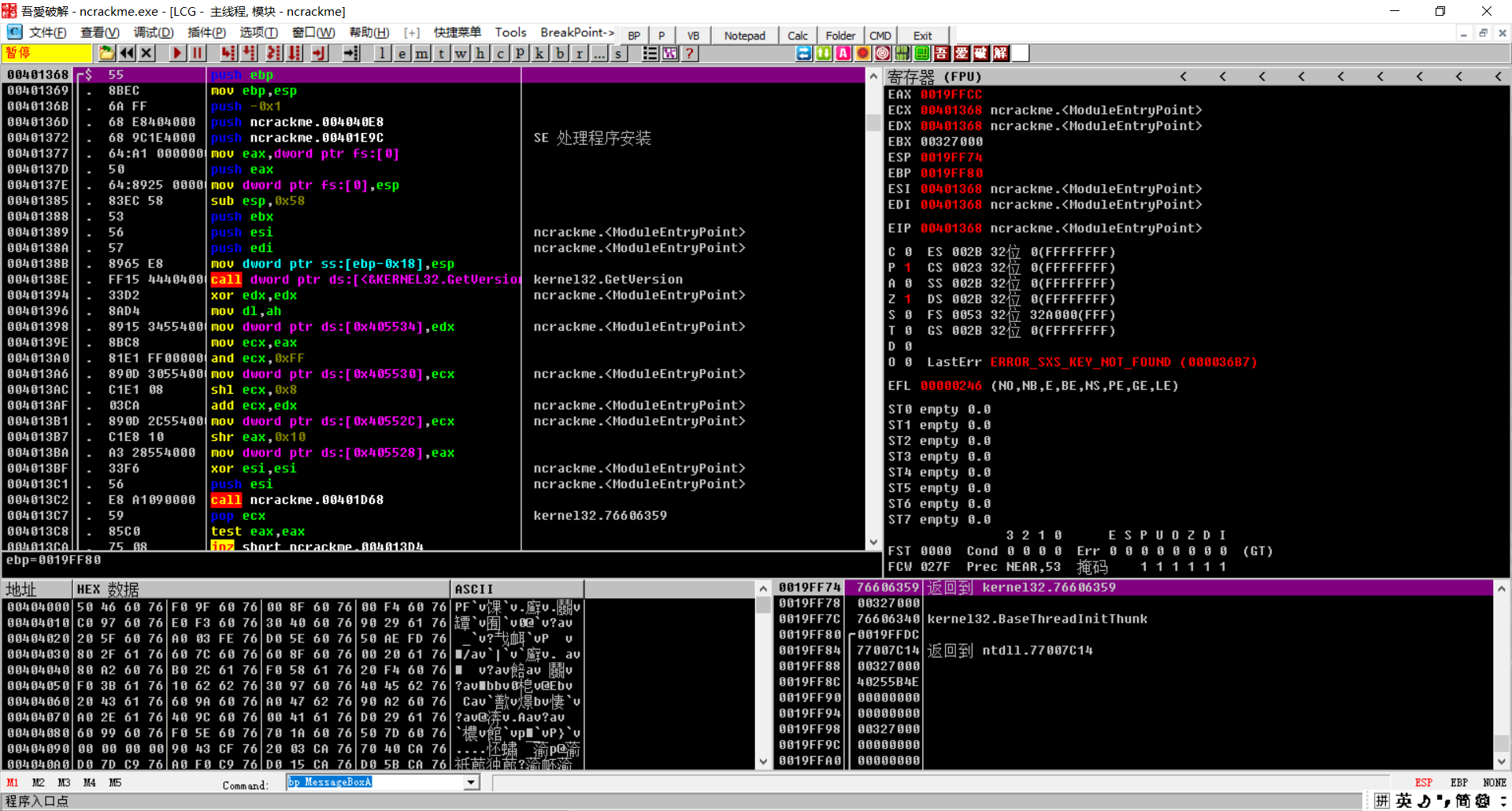
程序多数会用 GetWindowTextA,GetDlgItemTextA 这类 API 来得到文字方块里的字符串。程序弹出信息时候,这个信息由MessageBoxA 提供,bp MessageBoxA 直接下断
我们输入以下用户名,密码,点击register
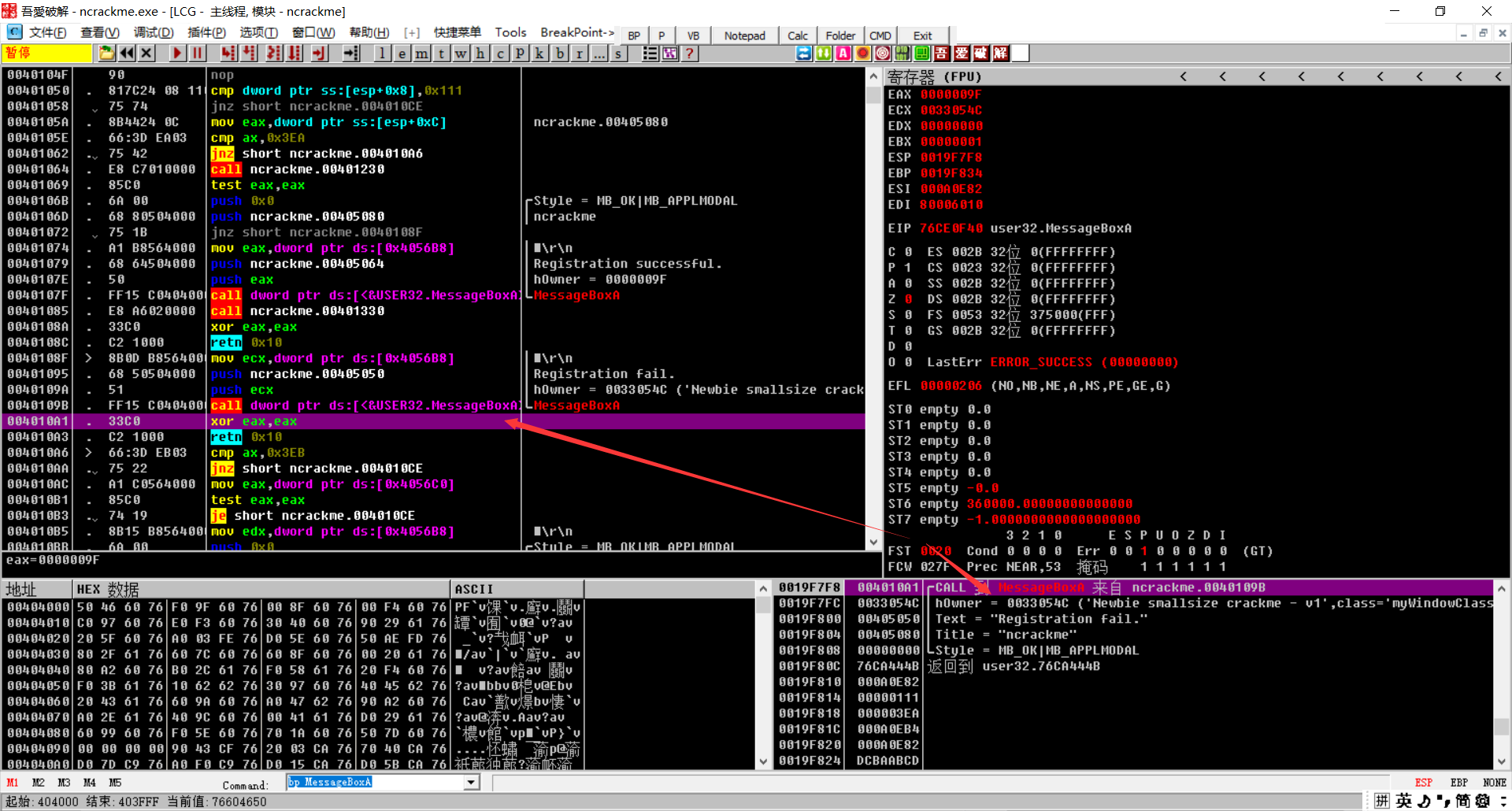
返回调用的反汇编窗口发现,这里有成功和失败的信息,正常来说我们直接把上面的jnz改成je就完事,但是我们需要分析序列号的算法,上面看test eax,eax就是想看看eax是不是0,所以这个程序最大的问题就是这个eax,那么我们猜测和 00401230有关,我们去看看
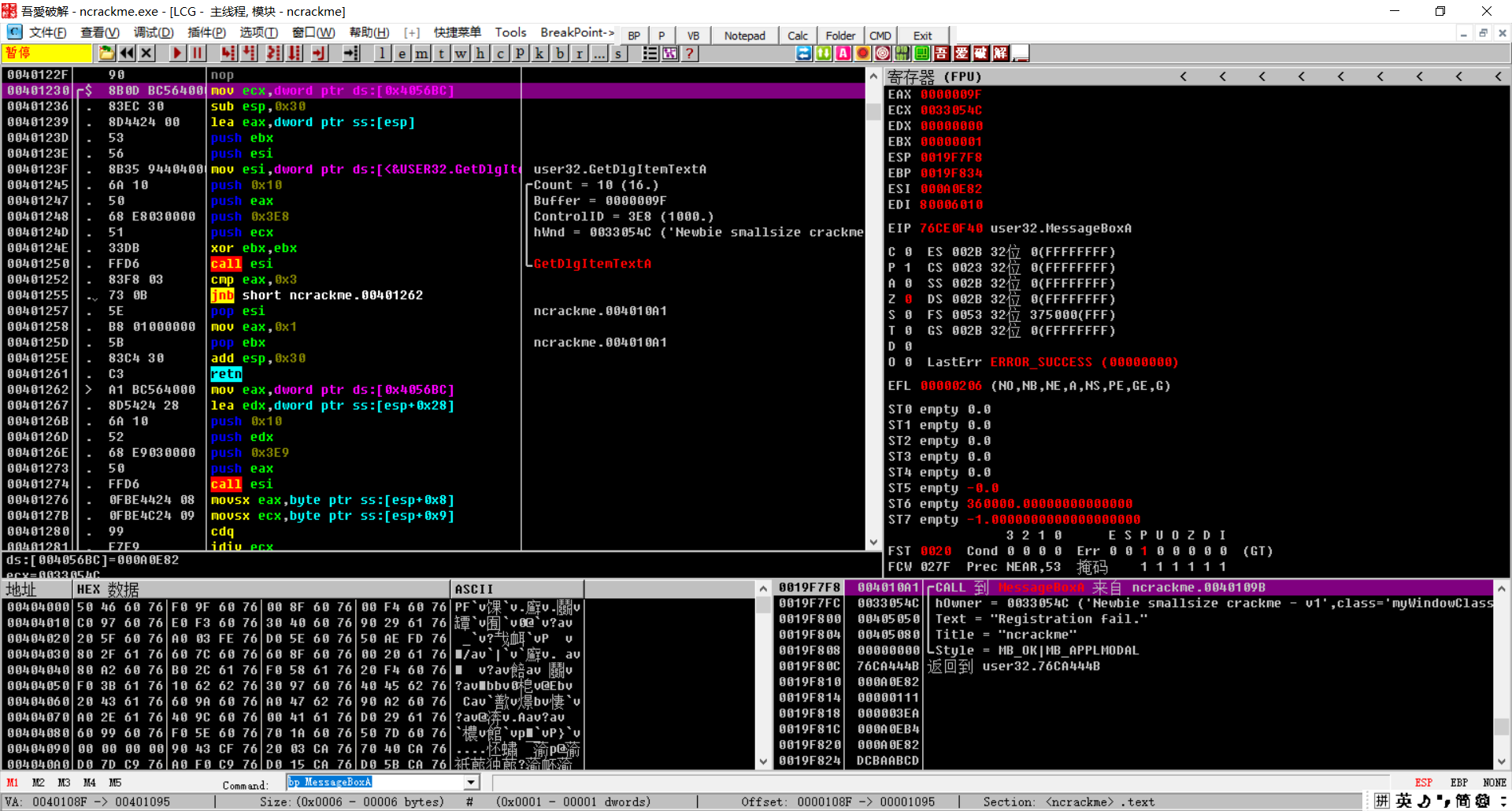
我们开始分析
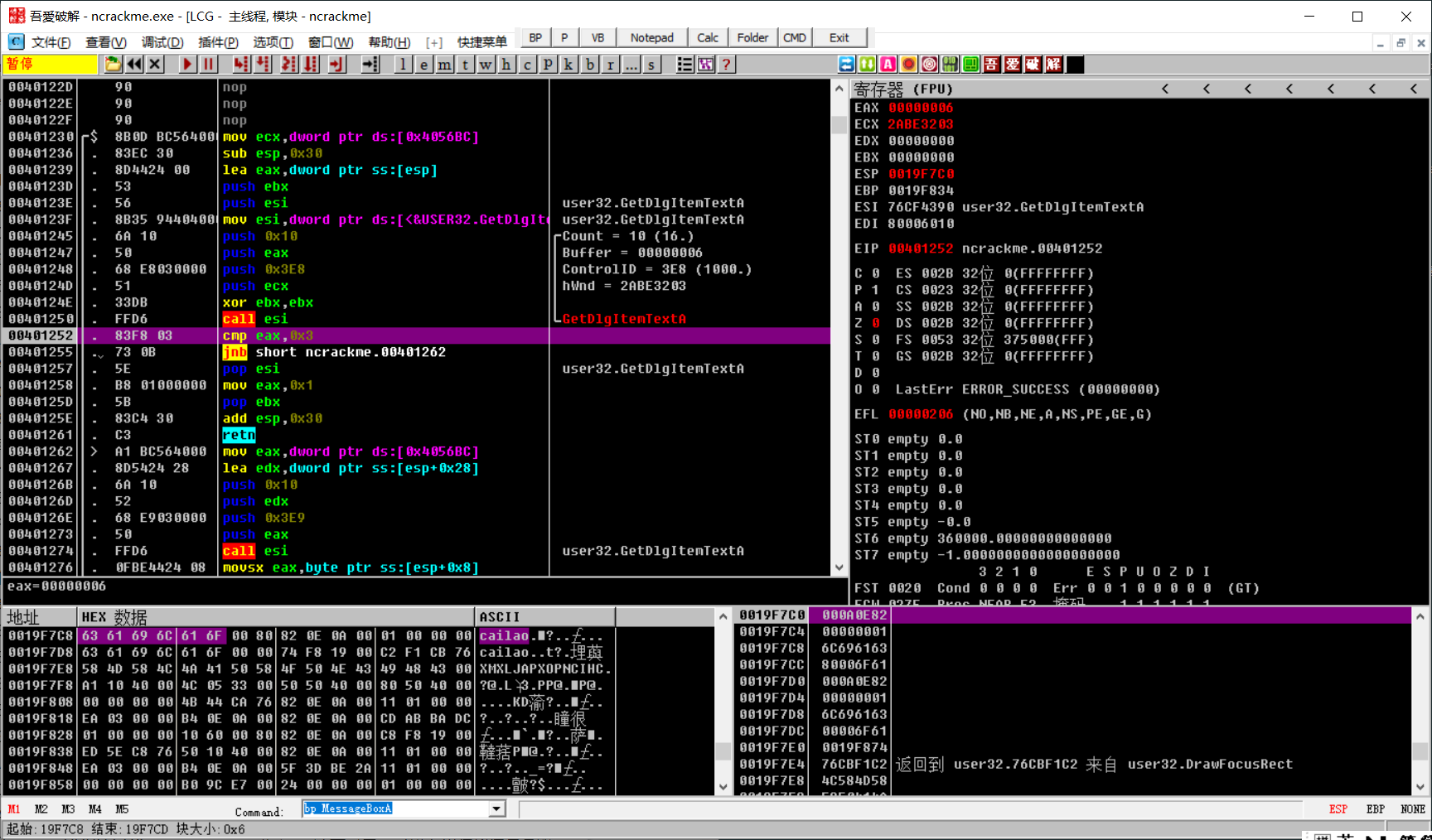
这里我们可以看到我们存放的用户名,eax为我们用户名的长度,进行比较,如果小于3直接失败,大于3才跳转,所以说用户名大于3
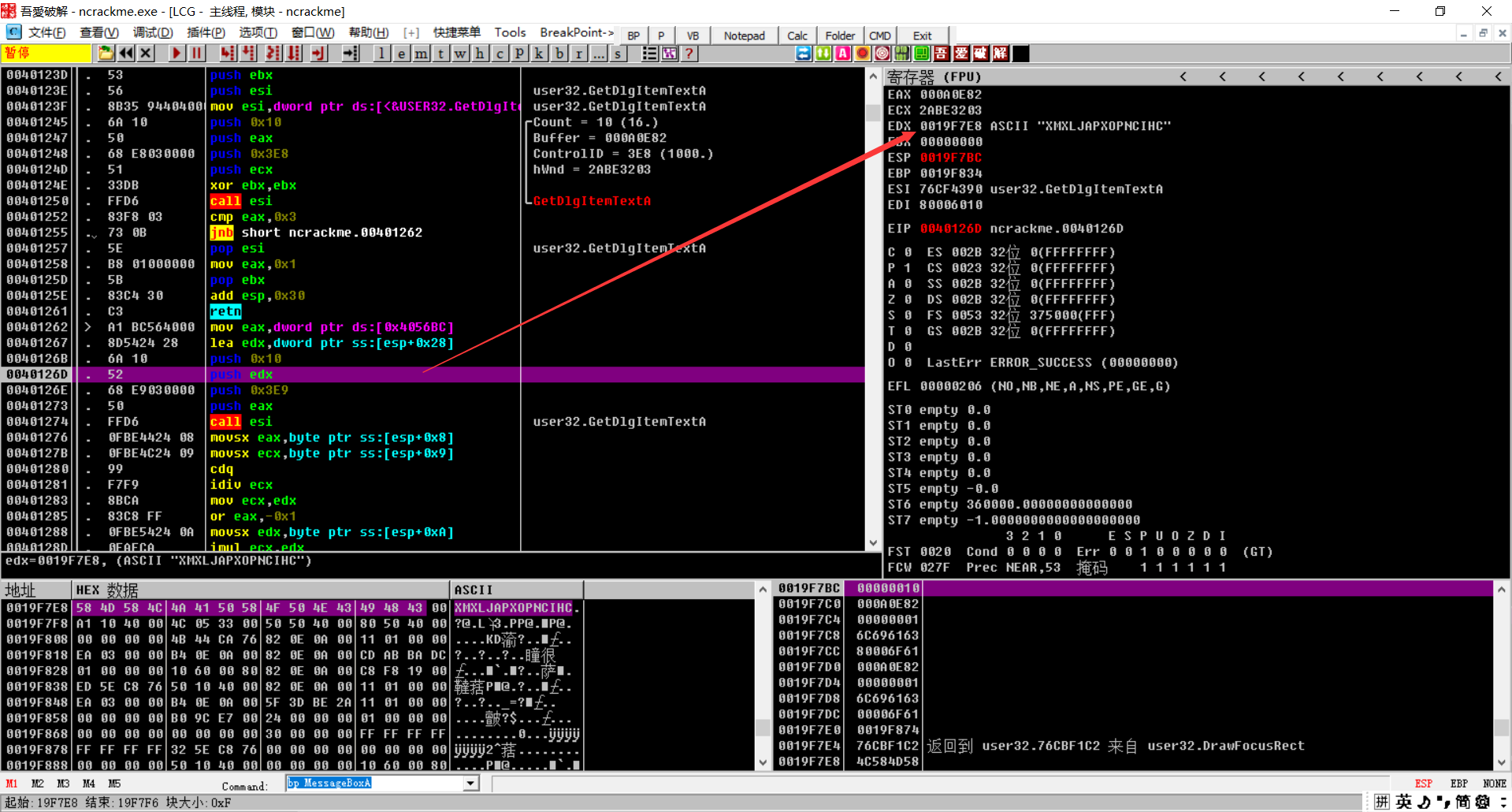
我们到这里可以看到这个位置是存放了序列号的字符
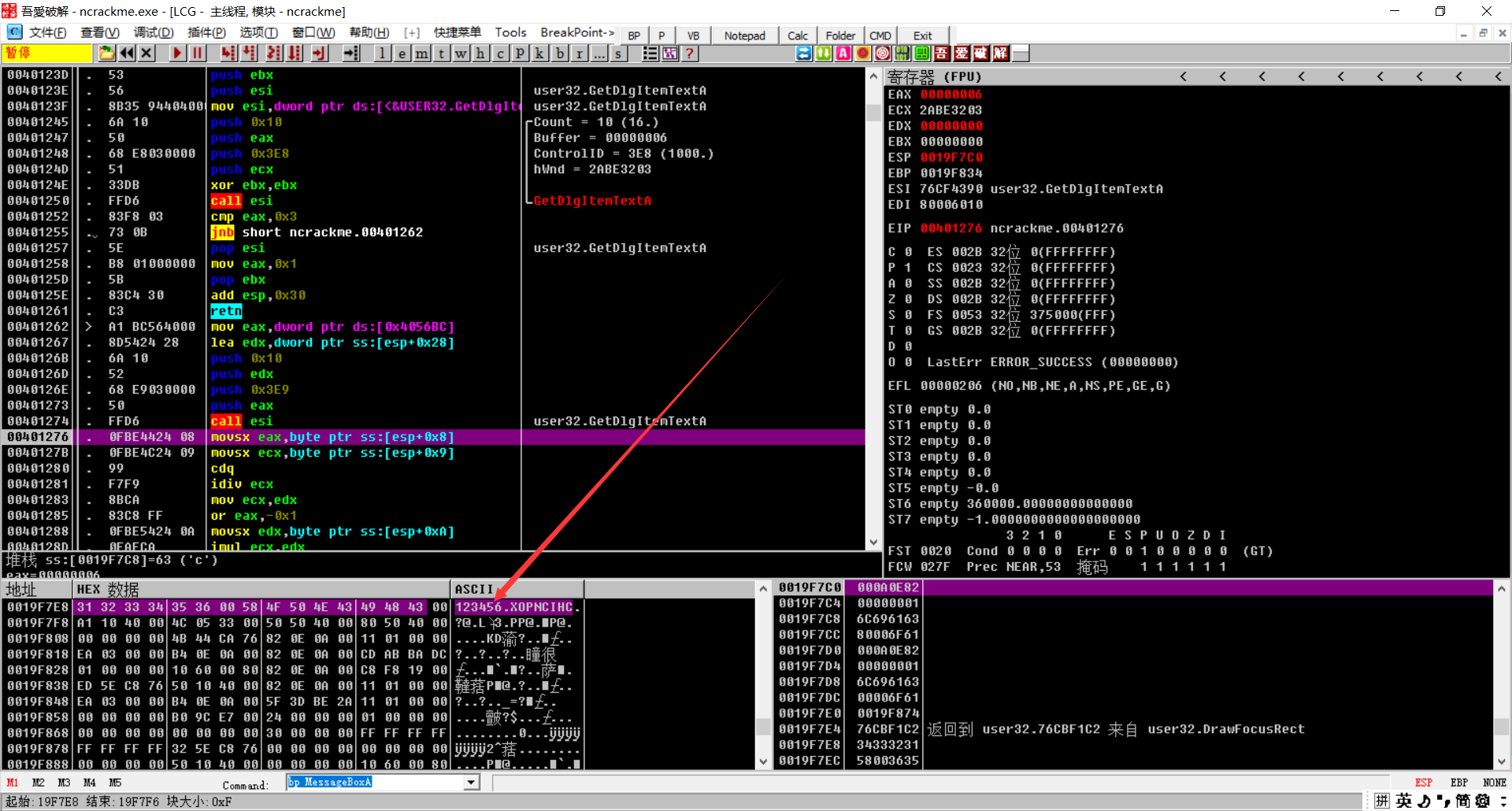
可以看到用GetDlgltemTextA得到序号
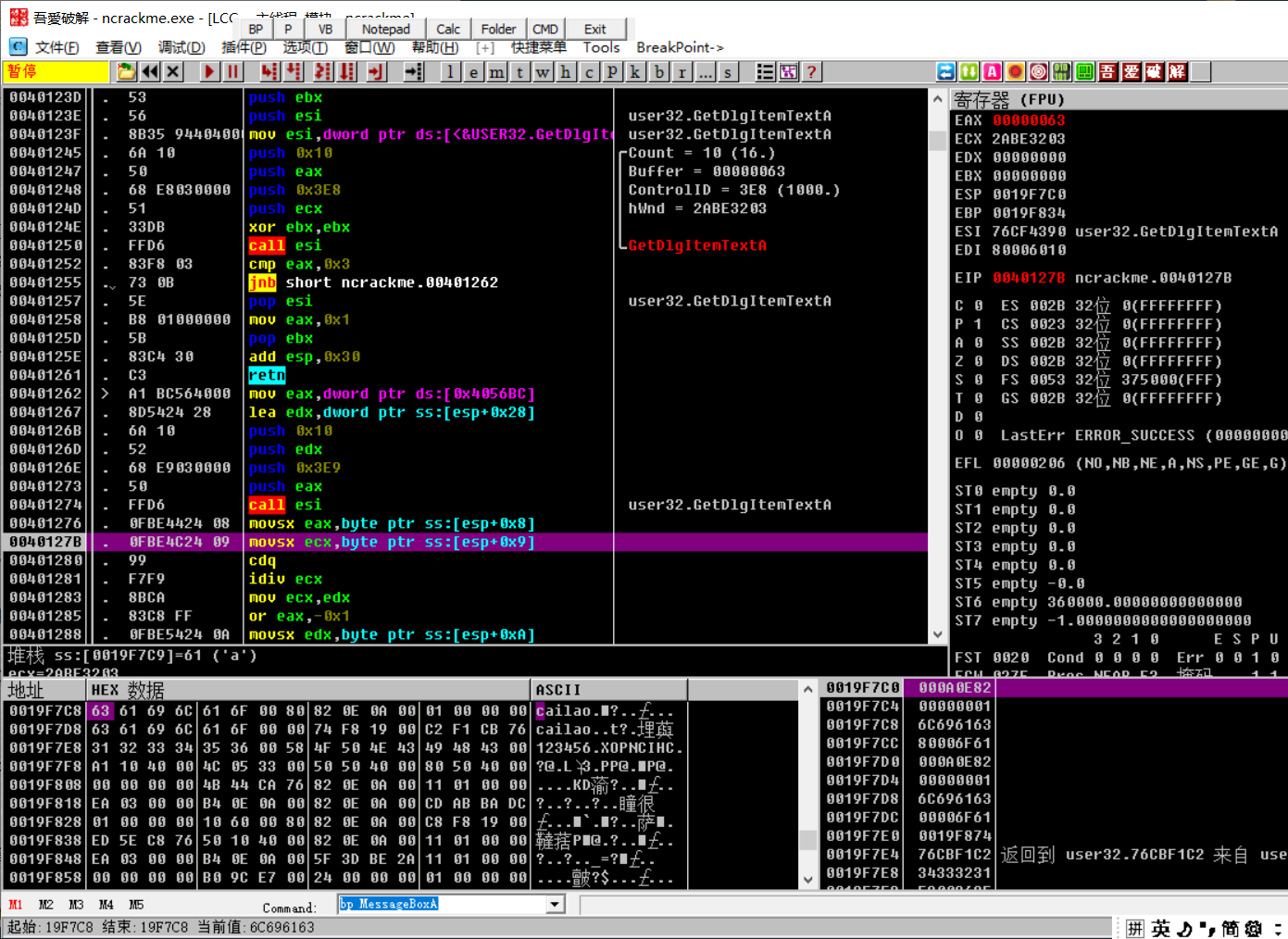
这个位置把我们的用户名的前两位放到了eax,ecx中
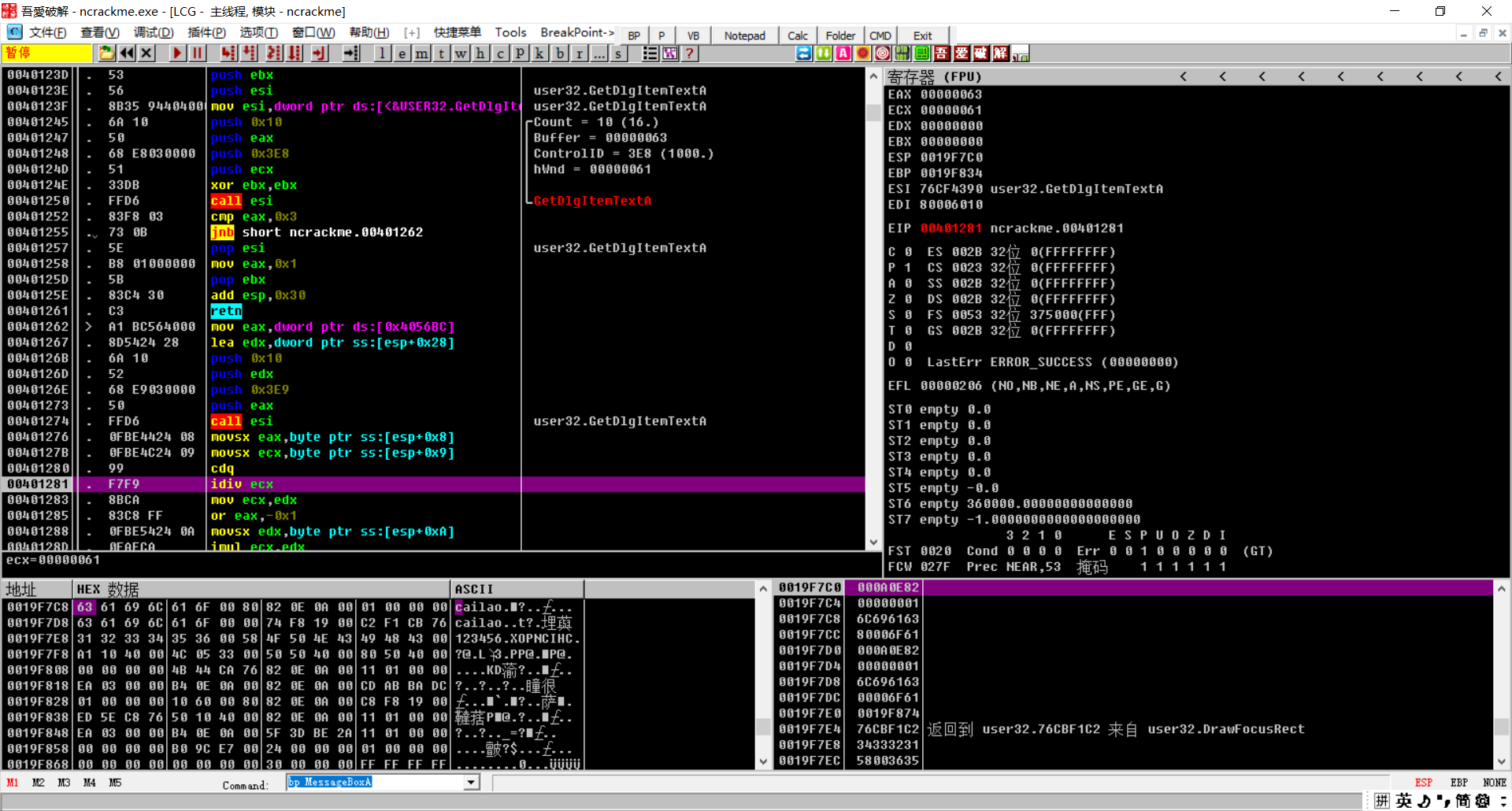
cdq将eax扩展为edx:eax,idiv ecx将 edx:eax除以ecx,余数放到edx中
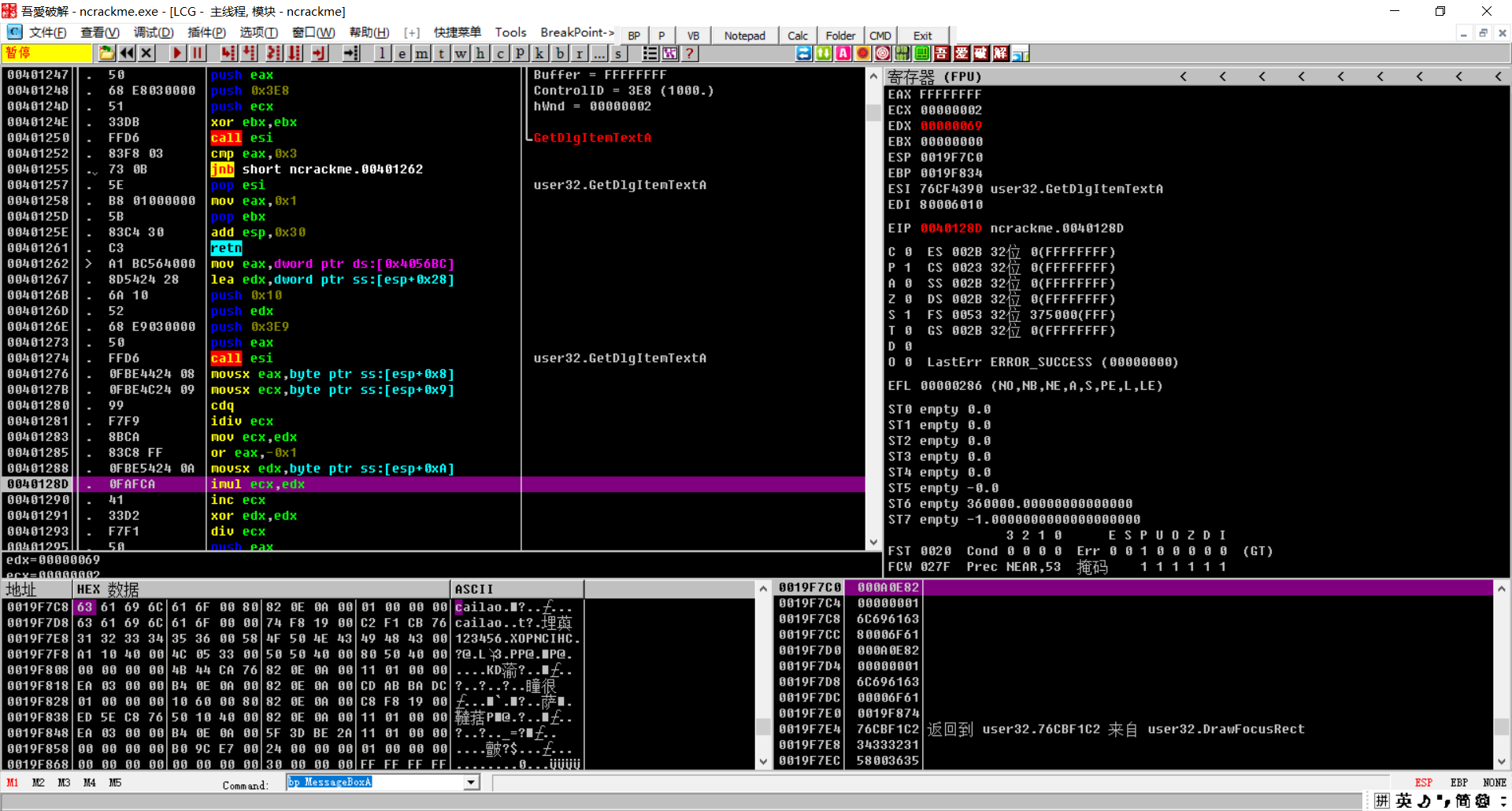
把名字的第三位放在edx中,刚才余数在ecx中,他们相乘
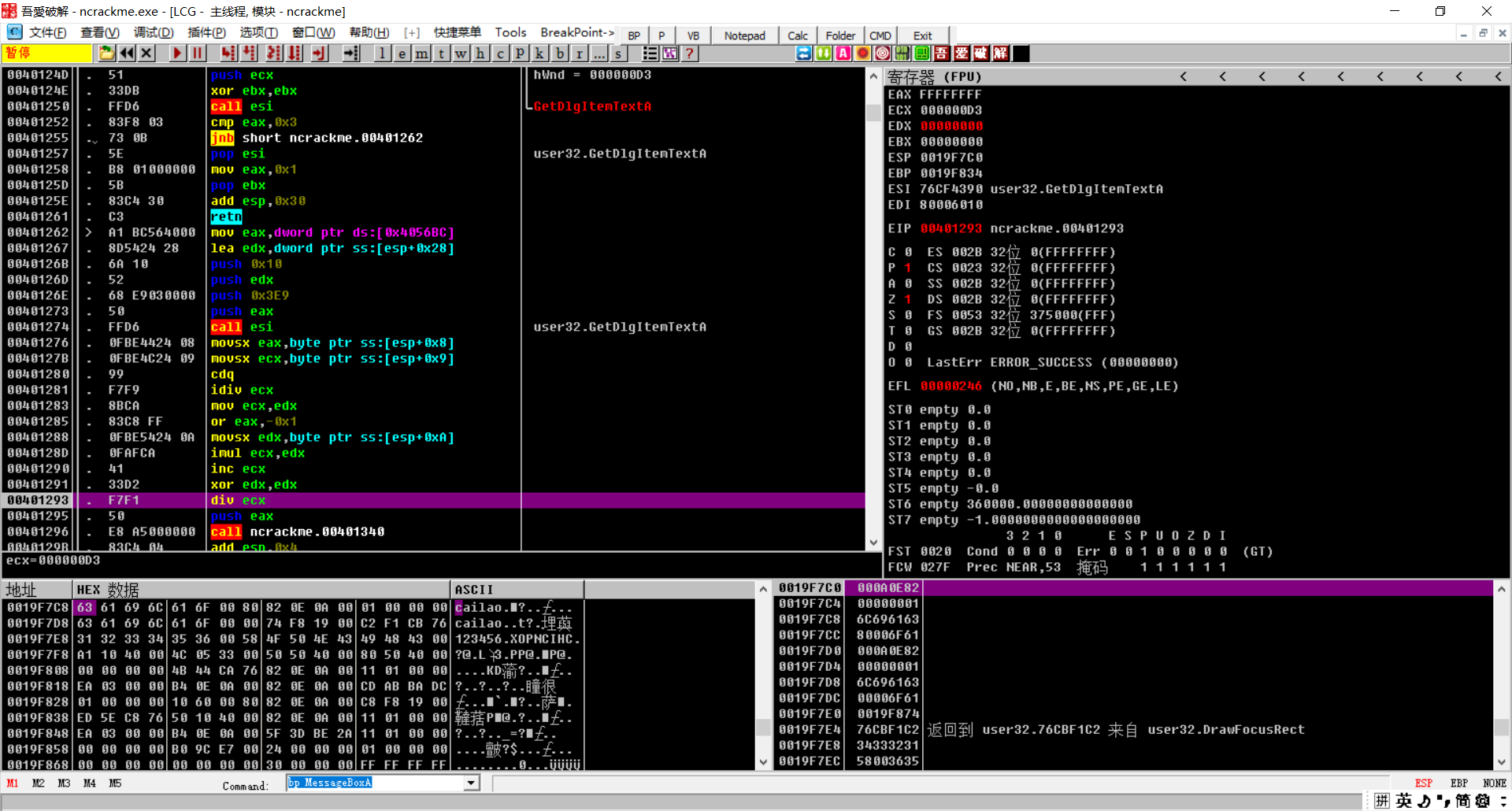
ECX自增1,EDX=0,EAX/ECX,推导成公式就是
$$
0xFFFFFFFF/(1+(arr[0]%arr[1]*arr[2]))
$$
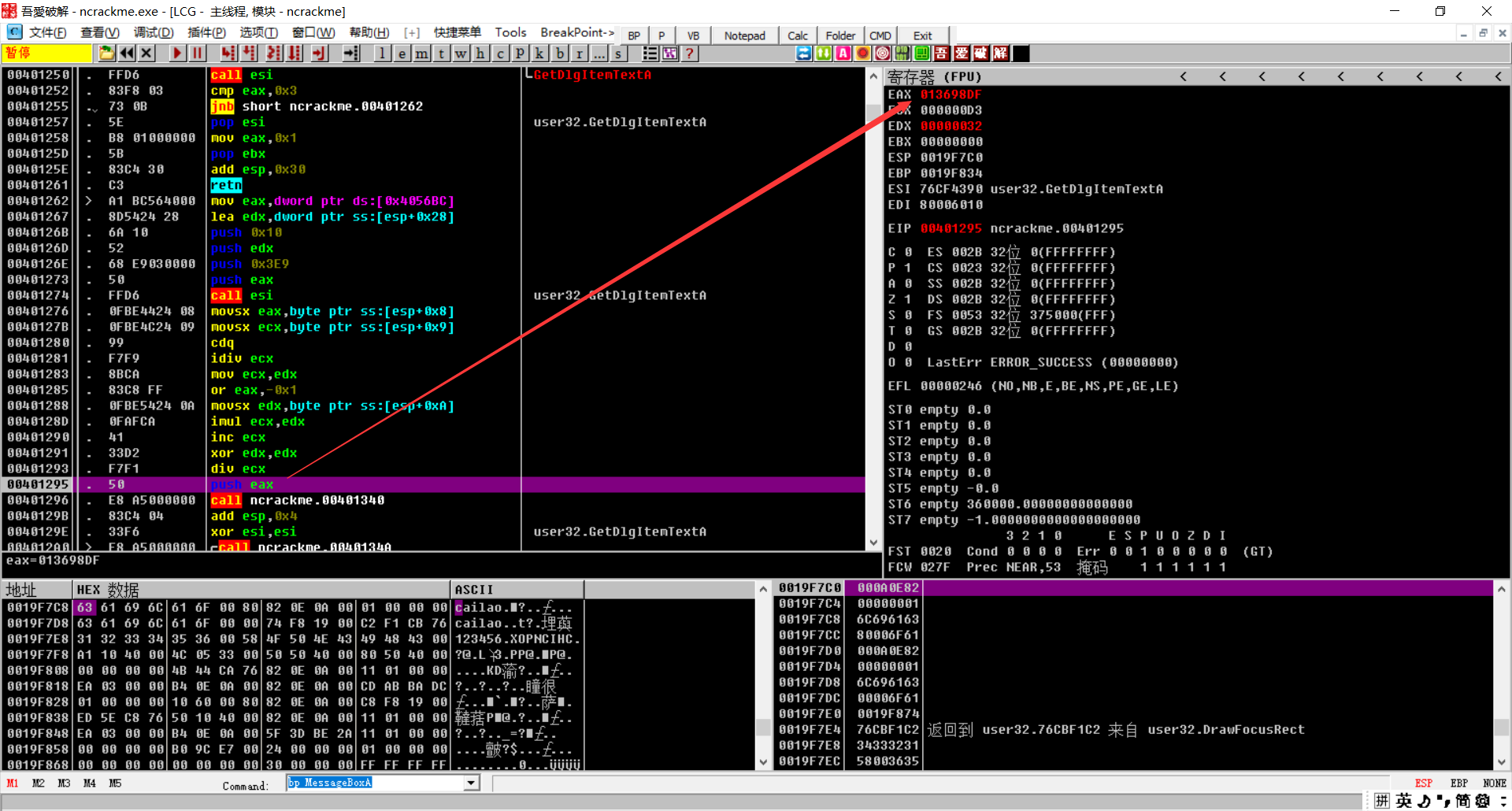
CALL 401340:
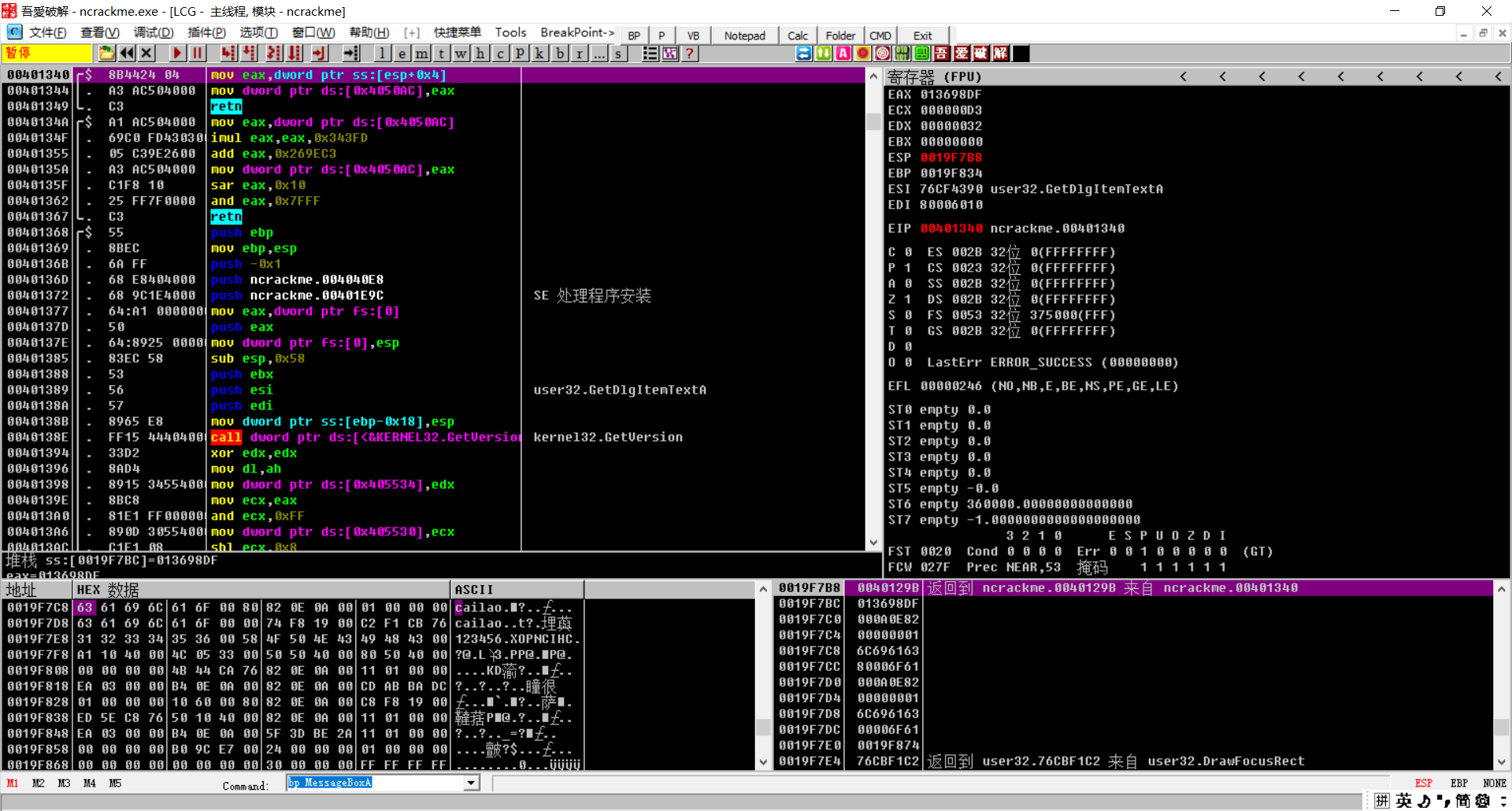
进行两个魔性的操作,ret返回了
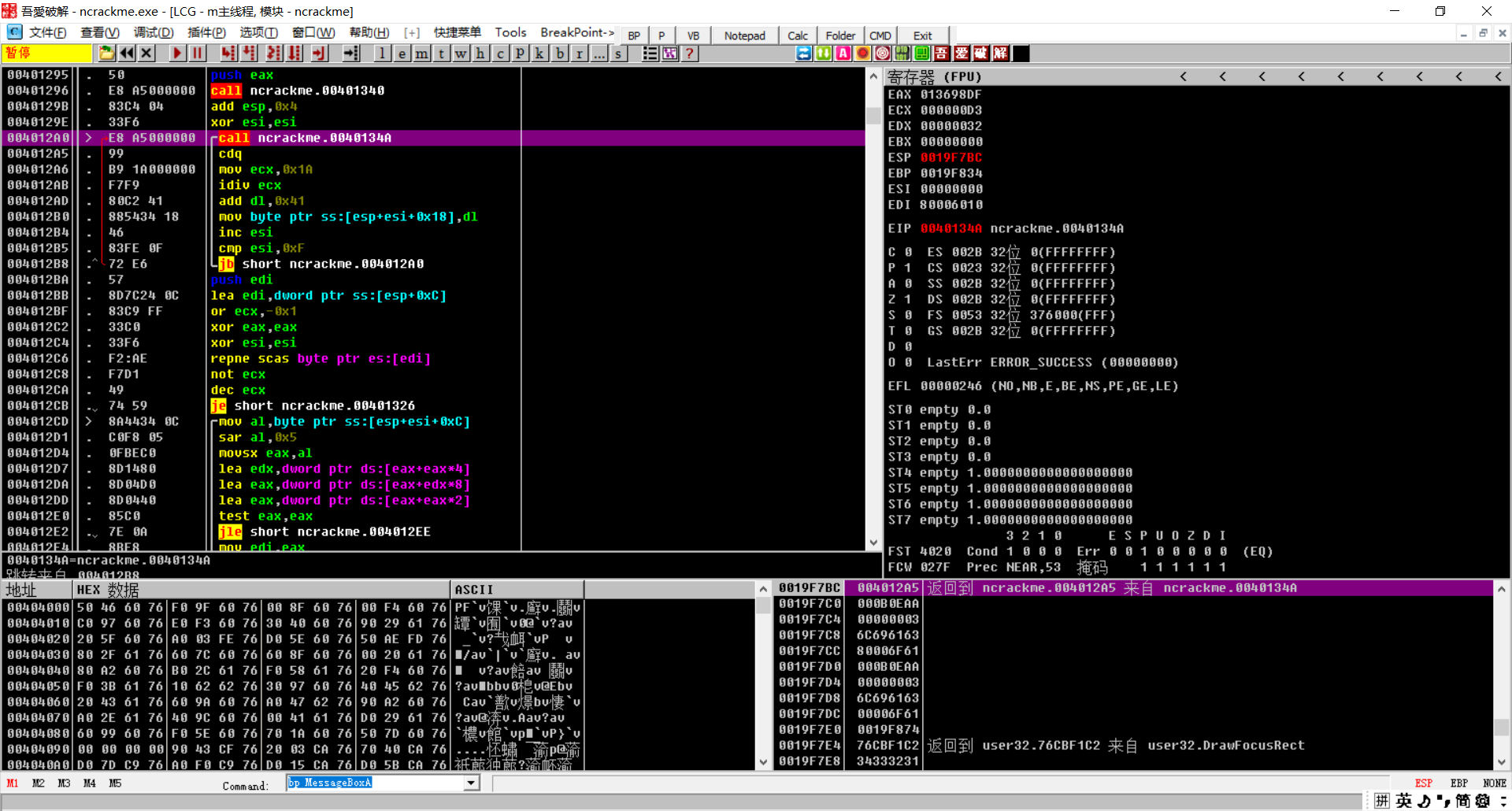
看一下 CALL 40134A:
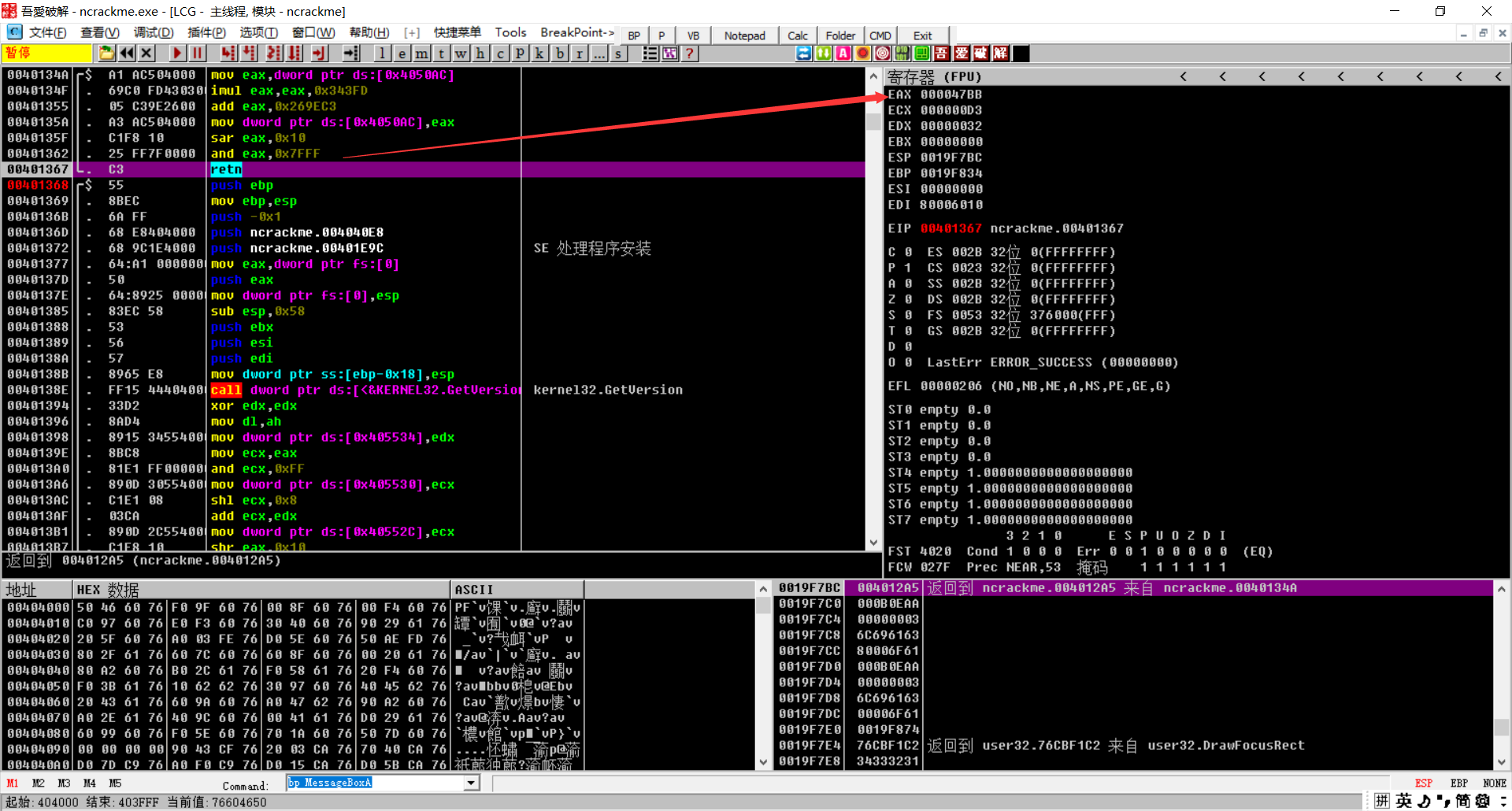
进行了一系列运算,等到47BB
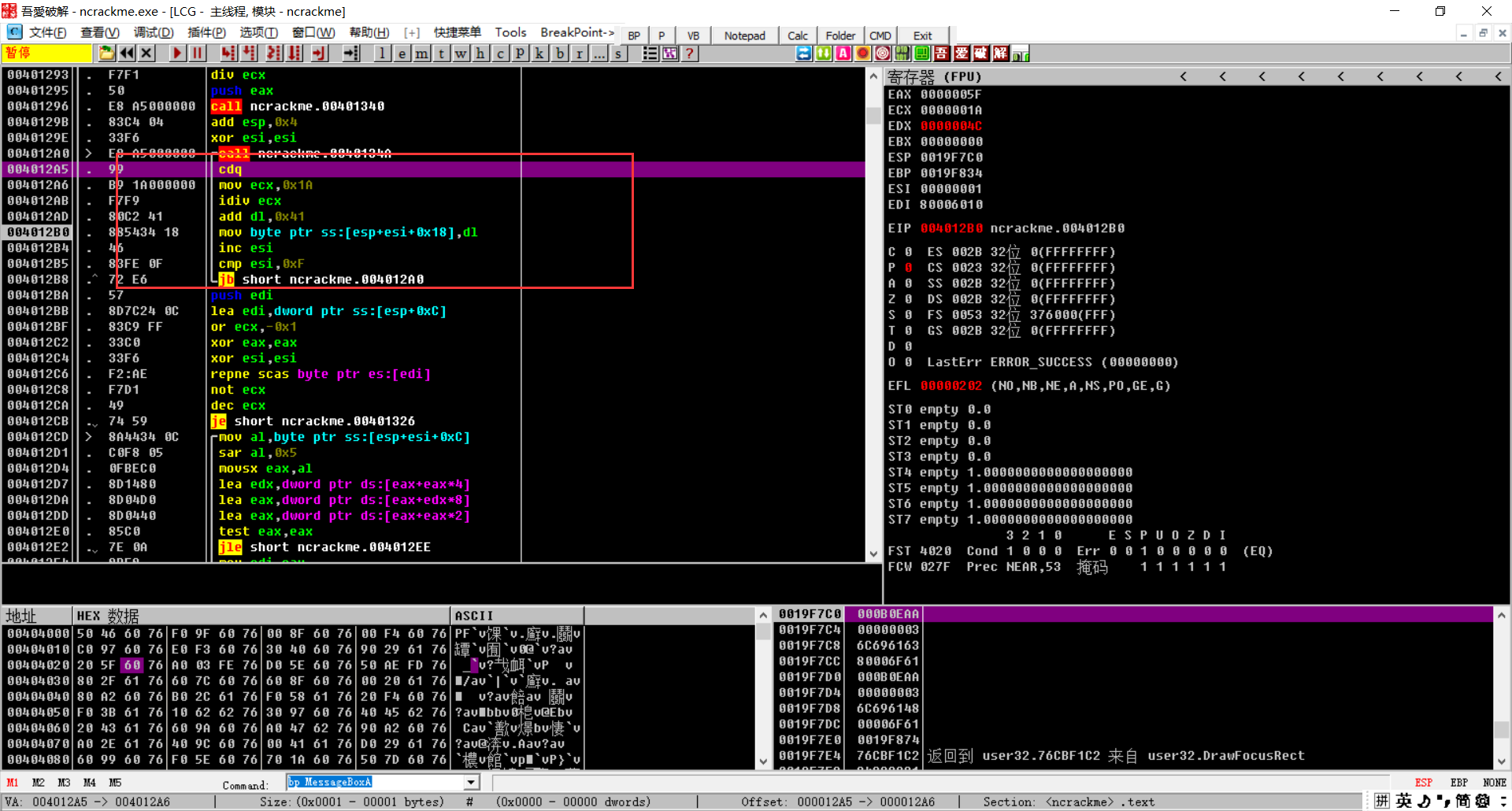
进行了把EAX原来的值扩展,(edx:eax%1a)+41将余数的下8位存到ESP+ESI+18,循环16次
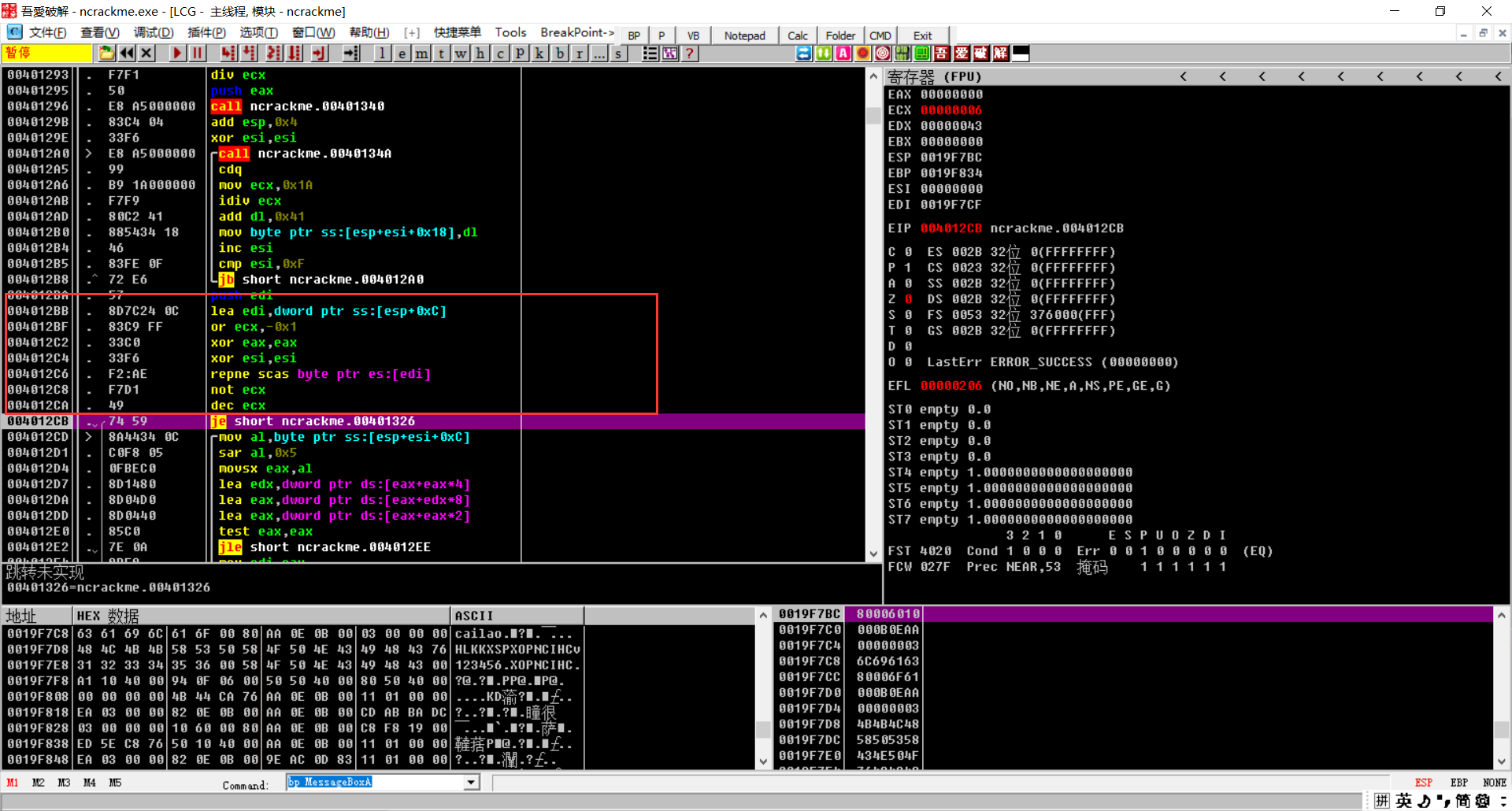
获取名字长度
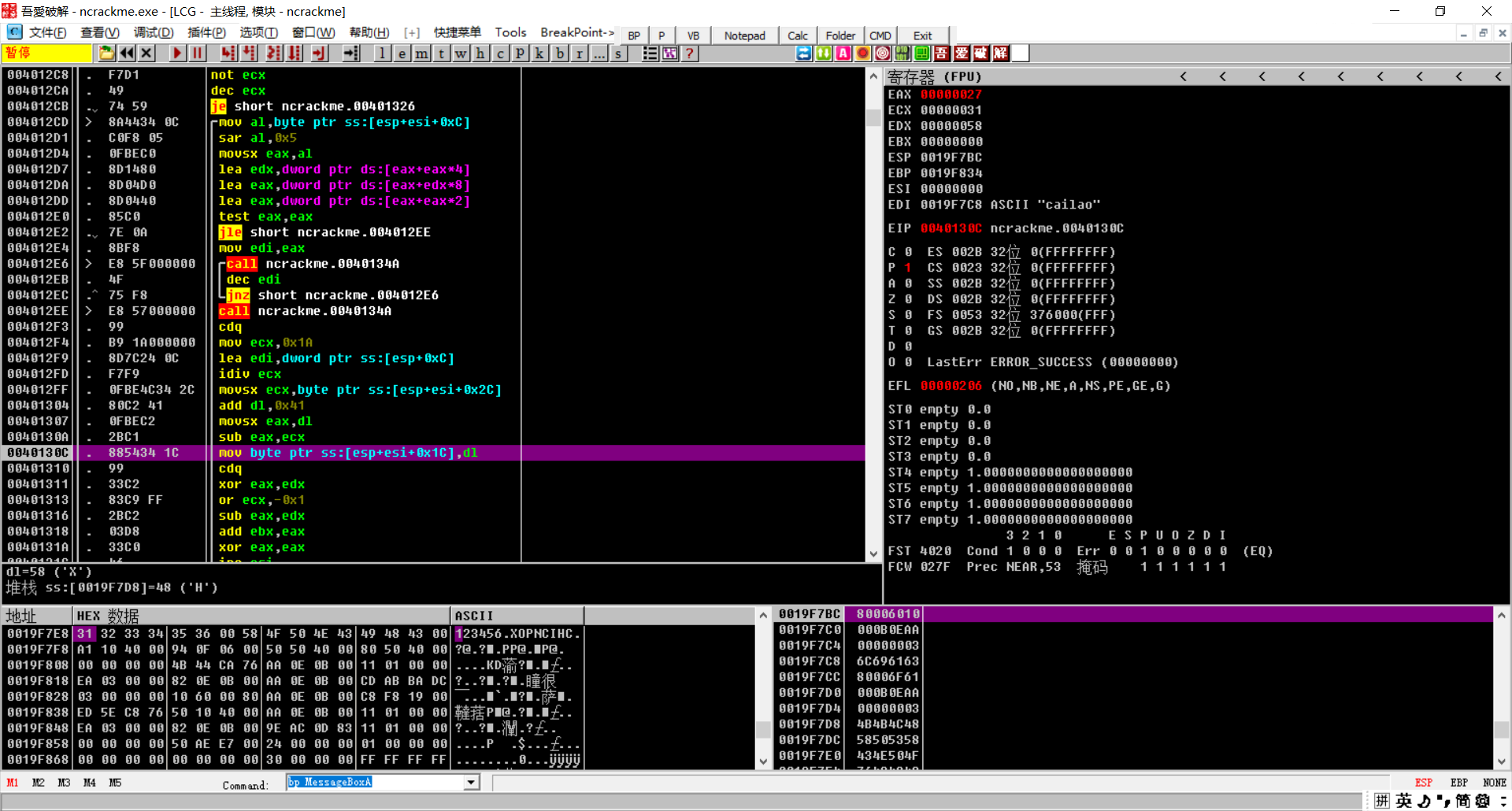
可以发现所有的东西都跟这个eax有关,所以我们需要所有循环的eax值就可以了
第 58 4D 58 4C 4A 41 满足6位密码
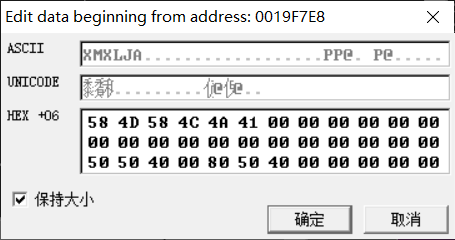
所以用户名为cailao时候密码为XMXLJA试一下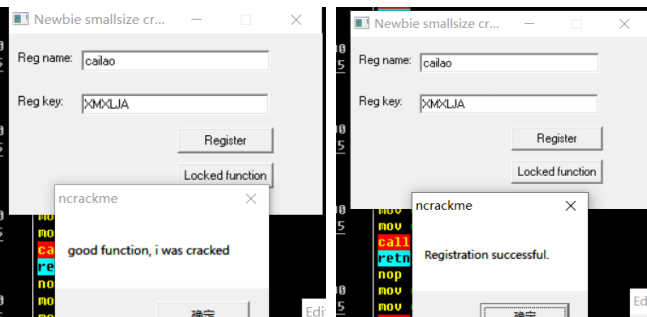
总结:今日任务完成了2/3,看雪的CTF没有复现😭,明天争取复现,可是明天要去吃🍛,估计又得搁置了!尽量完成明天,奥里给💪,👴是无敌的
4.22日更新
今日任务:滴水逆向+小黄书更新(看雪CTF暂时停更新)
👴今日,带了姑父洗澡,晚上恰饭,所以不知道能更新多少😭良心受到谴责
步入正题!
返回值是如何传递
返回值的类型和return回去的类型是匹配的,这里举了个例子
1 | char fun(){ |
和👴之前说的一样,用的寄存器就是EAX,AX , AL寄存器和返回值类型有关,这里直接看一下汇编代码,印象深刻一下
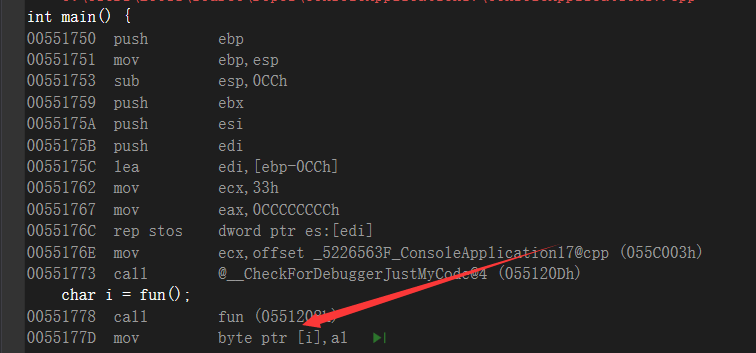
假设,我这边调用的时候的类型不同

直接用movsx进行补全就可以,类型转换,offset为偏移,可以看成具体的地址
如果这里是64位的,_int64,会将后8位放在eax中,前8位放在edx中
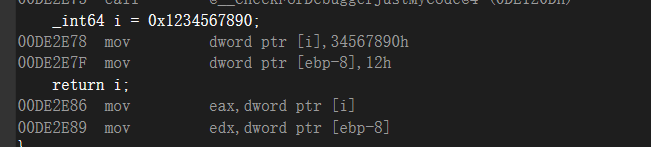
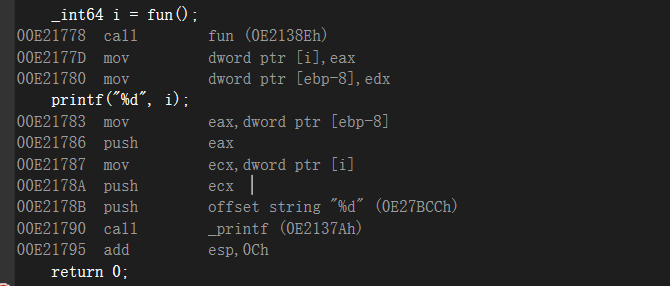
取出来的时候,先是把ebp-8的值给eax压入堆栈,再把i的那个局部变量的地址给了ecx,再把ecx压入堆栈,我们可以看到,我们是把eax压入当前的局部变量i那个位置,然后把edx压入ebp-0x8的放局部变量的那个位置
参数传递的本质
把值传递,用堆栈和寄存器来传都可以,调用约定,告诉编译器我们用的stdcall,cdecl,fastcall那些等等,这里需要注意的就是,我们函数传递的时候,我们假设定义的是一个字节,但是我们传递的时候,按照的是4个字节,因为堆栈每次都-0x4
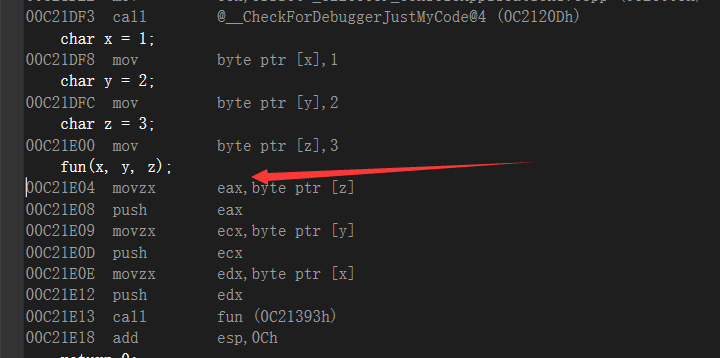
实际上传递都是int 4字节,原因就是本机尺寸的原理,比如说本机是32位的,他对32位的数据处理是最好的(这里用走路的步的大小做了个例子),编译器也遵守了这个规则,char和short根本没有节省空间,所以整数类型的参数,使用的就是int类型
总结:将上层函数的变量,或者表达式的值“复制一份”,传递给下层函数
局部变量的内存分配
当我们函数什么都不做的时候,默认给我们的分的缓冲区大小就是0x40
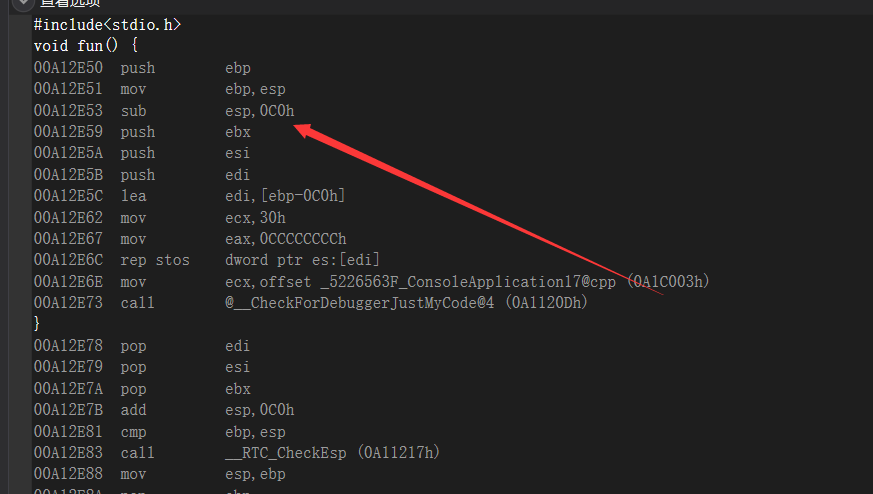
在vc++6.0中一般是0x40,但是我们换了一个编译器来说比如说我的是vs2019就是0xC0大小(默认分配的),如果我们需要假设一个int类型的值,我们看一下缓冲区怎么给我们进行分配的
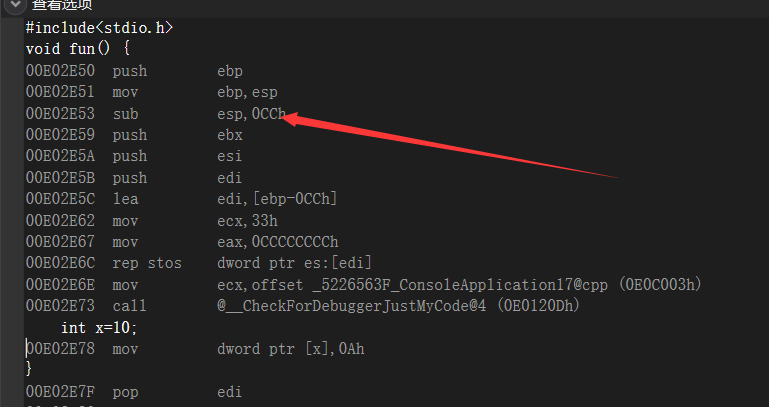
vs中是多了0xC,vc++6.0是多了0x4,多的多少跟数据类型无关,用多少个分多少个
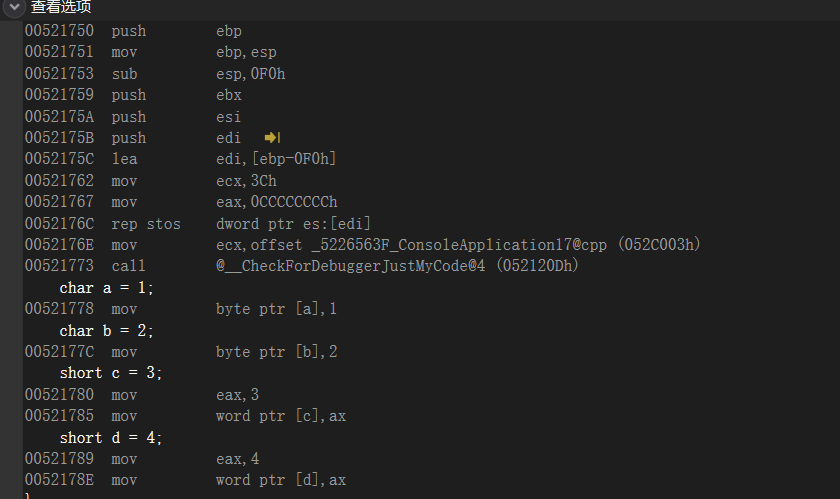

所以说不需要定义什么char和short的局部变量根本不会浪费空间,参数与局部变量没有任何区别,参数实在函数执行前,局部变量是在函数执行时,本质上讲参数和局部变量没什么区别:唯一区别是一个是ebp+,一个是ebp-
赋值语句的本质
将某个值存储到变量中的过程就是赋值
没错代码在汇编下面没有秘密可言!👍优先级问题,👴有小括号记什么优先级
数组的本质
假设我现在这么写代码,我们看一下反汇编
1 | int v_0 = 1; |
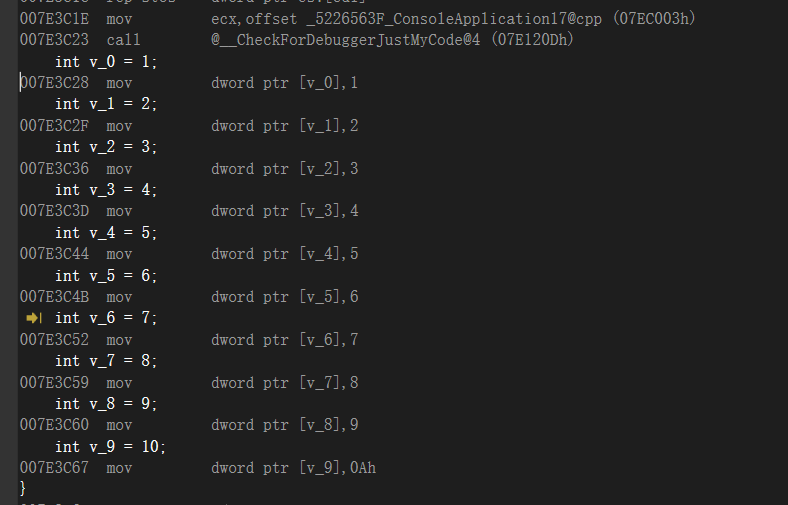
从 ebp-0x4开始一直往上开始存入,这么写比较麻烦,所以有一种简写方式,就是数组,我们去观察一下反汇编
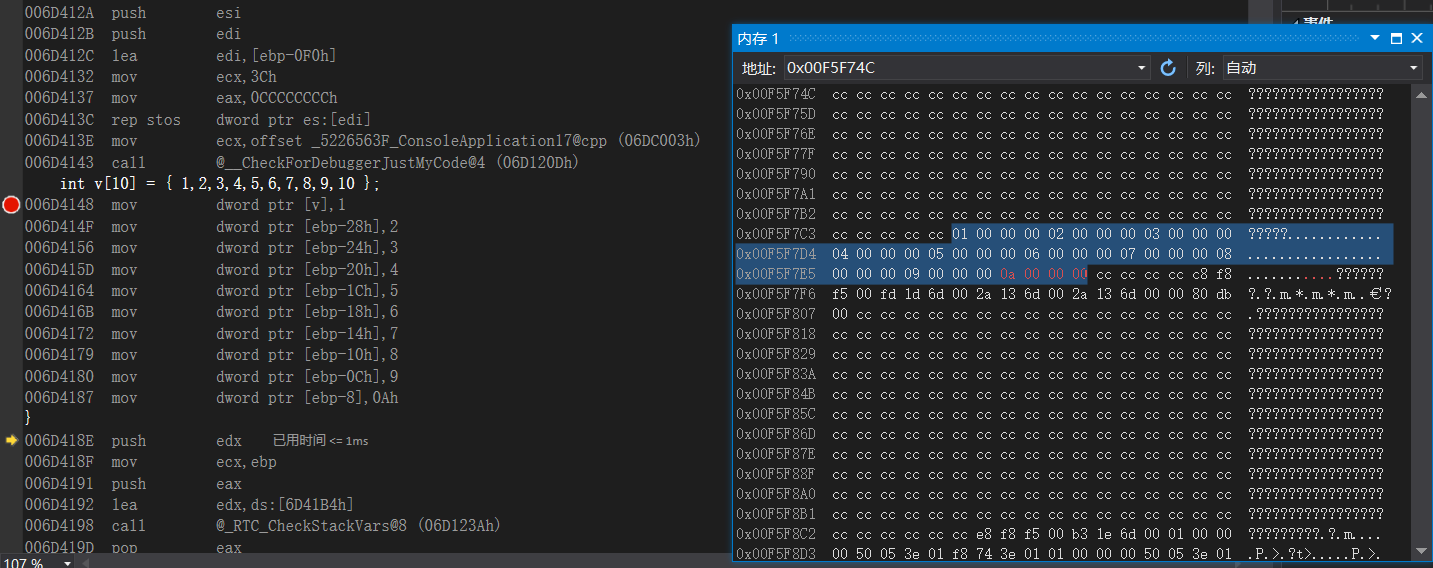
数据就是一排数据且等宽的变量,声明数组的时候[ ]里面的值必须用常量不可以用变量,因为比如说用了变量,我们这里写反汇编的代码的时候,不知道应该提升多少好(后面动态数组再说动态数组的问题)
👴看完了,大概今天讲的就是这些,溜溜球去看小黄书去
开始小黄书:
上次自己的问题就是 Opcode和menemonic对应的原则,群里的大佬给出了答案

👴准备开始看书啦!估计今天可以早睡觉!嘿嘿嘿嘿!
浮点数编码方式
浮点数编码采用的是IEEE规定的编码标准,IEEE规定的浮点数编码会将一个浮点数转换为二进制数,以科学计数法划分,将浮点数拆分为3部分:符号,指数,尾数
float类型的IEEE编码
float 4字节(32位),最高位用于表示符号:在剩余的31位中,从左向右取8位用于表示指数,其余用于表示尾数
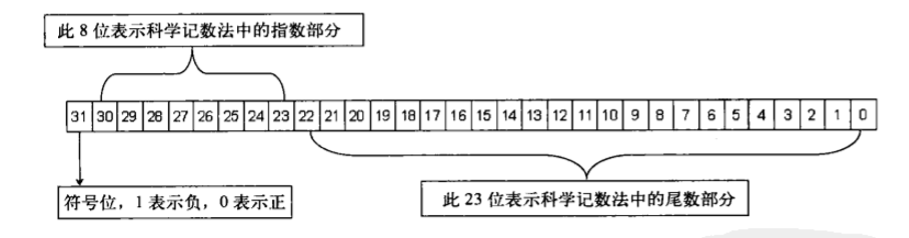
假设:12.25f 转化成对应的二进制数 1100.01,整数部分是1100,小数部分01,小数点向左移动,每移动一次指数+1,移动到除符号位的最高位为1处,停止移动,这里移动了3次,变成1.10001,指数部分为3,在IEEE编码规则瞎,最高位一定是1的,所以如果这里如果是整数符号位就填写0
12.25f 经过IEEE转换后情况:
符号位:0
指数位:十进制 3+127,转换为二进制是10000010 这里👴又不懂了,去看看为什么是+127,🏃♂️回来了:由于指数可能出现负数,十进制数127可表示为二进制数01111111.IEEE编码方式规定,当指数域小于01111111时为一个负数,反之为正数,因此01111111为0(MD,书的下一页有!脑瘫小源源在线百度 哈哈哈😂搞明白就行)
尾数位10001 000000000000000000 (不足23位的时候,低位补0填充)
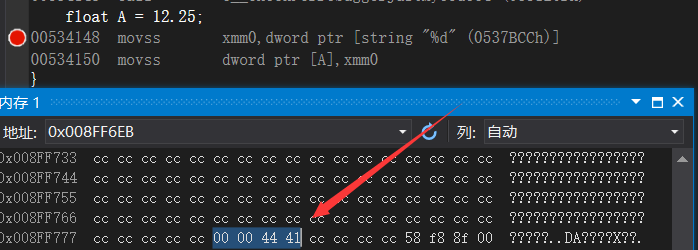
变换成16进制位0x41440000,由于小端序所以内存变成了这个样子
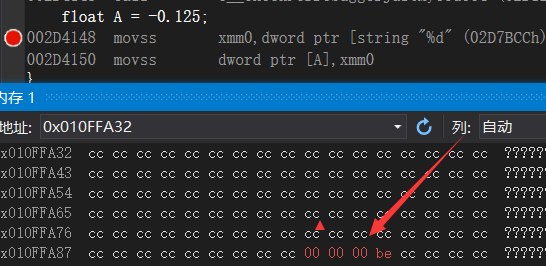
-0.125f 经过IEEE转化后的情况
符号位:1
指数位:127+(-3),二进制 00011000,如果不足8为,则高位补0
尾数位:00000000000000000000000
转化为16进制为0xBE000000
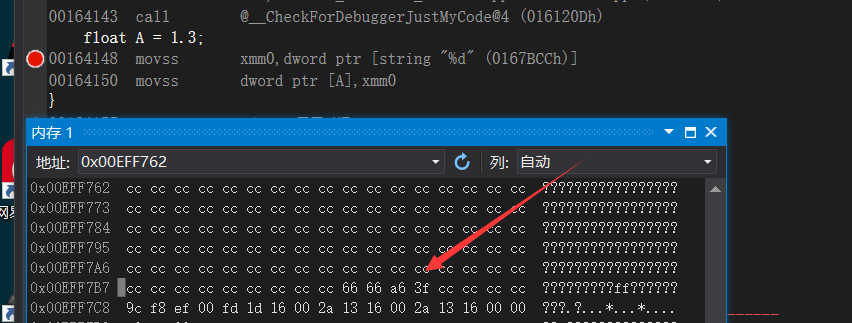
1.3f 经过IEEE转化情况 (1.3f转化比较奇怪,因为小数部分是一直有,由于规则尾数部分所以到23位停止的:0.3 0.6 1.2 0.4 0.8 1.6 1.2 0.4…)
符号位:0
指数位:127+0 二进制 01111111
尾数位:010011001001100100110
转化为16进制为0x3FA66666
所以说这个浮点数计算是一个近似值,存在一定的误差,如果把这个转化成小数的话,那么就是 1.299999523162841796875 四舍五入之后为1.3,所以这就解释了为什么C++在比较浮点数值是否为0时候,要进行一个区间比较,并不是等值比较
浮点数比较代码
1 | float fTemp = 0.0001f; //精确范围 |
double类型的IEEE编码
double类型为8字节 64位 指数11位 剩余52位标识位数 double中的指数为+1023 用于指数符号的判断,剩下的 同float
基本浮点数指令
浮点数操作是通过浮点寄存器来实现的,浮点寄存器通过栈结构来实现,由ST(0) ---- ST(7)的8个栈空间组成,每个浮点寄存器占8个字节,每次使用浮点寄存器的时候先使用ST(0),不能越过ST(0)直接使用ST(1),当ST(0)存在数据时,执行压栈操作后,将ST(0)的数据装入ST(1),如果没有出栈的操作就一直压,一直到浮点寄存器占满 IN表示操作数入栈,OUT表示操作数出栈
指令表
| 指令名称 | 使用格式 | 指令功能 |
|---|---|---|
| FLD | FLD IN | 将浮点数IN压入ST(0)中,IN (mem 32/64/80) |
| FILD | FILD IN | 将整数IN压入ST(0)中,IN (mem 32/64/80) |
| FLDZ | FLDZ | 将0.0 压入ST(0)中 |
| FLD1 | FLD1 | 将1.0压入ST(0)中 |
| FST | FST OUT | ST(0)中的数据以浮点形式存入OUT地址中 OUT (mem 32/64) |
| FSTP | FSTP OUT | 和FST作用一样,但是会执行一次出栈的操作 |
| FIST | FIST OUT | ST(0)数据以整数形式存入OUT地址中 OUT (mem 32/64) |
| FISTP | FISTP OUT | 和FIST指令一样,但是会执行一次出栈的操作 |
| FCOM | FCOM IN | 将IN地址数据与ST(0)进行实数比较,影响对应的标记为 |
| FTST | FTST | 比较ST(0)是否为0.0,影响对应标记位 |
| FADD | FADD IN | 将IN地址内的数据与ST(0)做加法运算,结果放到ST(0)中 |
| FADDP | FADDP ST(N),ST | 将ST(N)中的数据与ST(0)中的数据做加法运算,N为 0-7 ,先执行一次出栈操作,然后将相加的结果放入ST(0)中 |
使用浮点指令的时候,都要用ST(0)先进行运算,如果ST(0)中有值时,会将ST(0)中的数据向下存放到ST(1)中,然后再将数据放到ST(0)中,如果再次执行ST(0),那么就把ST(1)放到ST(2)中,如果8个寄存器都有值,继续像ST(0)存入数据的时候,我们会舍弃ST(7)的数据
这里介绍个C语言函数:_ftol将float型转化为int型
1 | //c++源码对比,argc为命令行参数 |
总结:float类型浮点数,占4个字节,但是都是以8个字节方式处理即double形式,当浮点数作为参数的时候,不能直接压入栈,push传的4字节,会丢失4个字节,所以printf使用整数方式输出浮点数会报错,printf以整数方式输出的时候,将对应参数作为4字节数据,按照补码的方式解释,而压入参数为浮点数类型的时候,数据长度为8字节,需要按浮点编码方式解释
浮点数作为返回值
1 | //c++源码对比,返回值为浮点数的函数调用 |
类型转换函数_ftol的实现
1 | //提升堆栈 |
字符和字符串
字符串的结束标记为’\0’,每个字符都记录在一张表中,他们各自对应了一个编号,系统通过标号来找到对应的字符来显示,👴一看这不说的ASCII码表吗
VC++6.0中,char定义ASCII编码格式字符,wchar_t定义Unicode编码格式的字符,如果wchar_t保存ASCII编码,不足位补0,假设’a’ ASCII码 0x61 那么Unicode就是0x0061
汉字编码使用ASCII GB2312-80 保存6763常用汉字编码 Unicode 使用UCS-2 为了让汉字都容纳进来,使用的两个Unicode编码解释一个汉字,UCS-4
VC6.0,为了使char于wchar_t通用,使用了预编译宏TCHAR来代替他们,TCHAR会根据编译选项定义对应的字符类型,👴还是第一次知道
字符串的存储方式
确定字符串的总长度有两种方法:
- 在首地址的4字节中保存字符串的总长度
- 在结尾处规定一个特殊字符
优缺点
- 保存总长度
- 优点:不需要遍历每个字符,取前n个字节就可以知道总长度,一般来说就是(1,2,4)字节
- 缺点:不能超过n的长度,且要多开销n字节,通信情况,双方需要事先知道通信字符串的长度
- 结束符
- 优点:没有记录开销,设计通信可以通过实际情况来决定
- 缺点:获取字符时候要遍历所有字符,比较慢
C++使用结束符’\0’为字符串结束标识,ASCII码使用1个字节\0,Unicode使用两个字节\0,不能使用ASCII的处理函数对Unicode处理,会报错
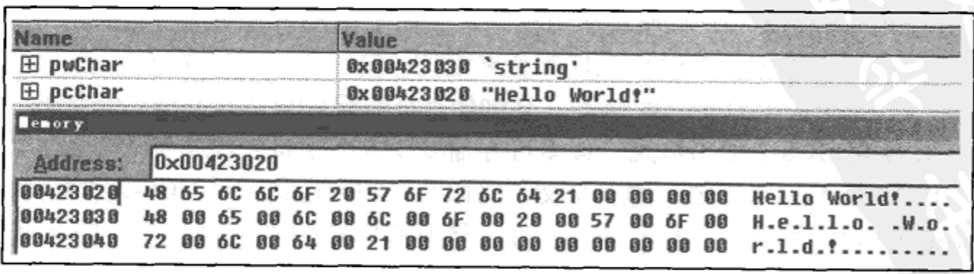
一般程序中会使用一个字符型指针来保存字符串首地址,char* wchar_t* TCHAR*
IDA这里有个操作是快捷键A,直接分析到’\0‘,解释字符串!👍我也是第一次知道这个东西
布尔类型不说了!👴会 (内存占1位 0 1)
地址,指针,引用,👴提一句吧,地址就是&那个,只有变量才存在内存地址,常量给爷🔪,(除了const 嘿嘿嘿),指针用来保存地址的,引用就是取别名,别名的操作就是对源变量的操作
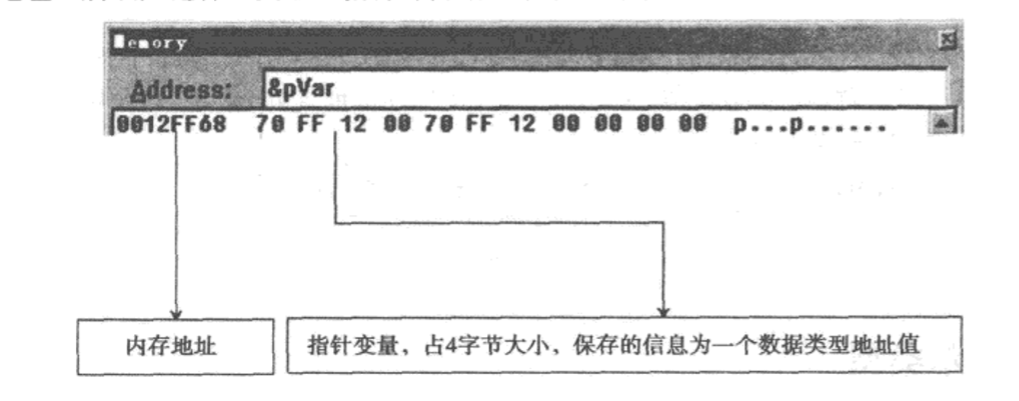
指针和地址的区别关系:
👴放个图就懂了:
不同点:
| 指针 | 地址 |
|---|---|
| 变量,保存变量地址 | 常量,内存编号 |
| 可修改,再次保存其他变量地址 | 不可以修改 |
| 可以对其执行地址操作得到地址 | 不可以执行取地址操作 |
| 包含对保存地址的解释信息 | 仅仅有地址值无法解释数据 |
相同点:
| 指针 | 地址 |
|---|---|
| 取出指向地址内存中的数据 | 取出地址对应内存中的数据 |
| 对地址偏移后,取数据 | 偏移后取数据,自身不变 |
| 求两个地址的差 | 求两个地址的差 |
👴整理完啦,今天拔了罐,特别疼,呜呜呜,后背难受!看雪CTF果断搁置了!
👴睡不着,于是乎做一下buu的
[FlareOn6]Memecat Battlestation

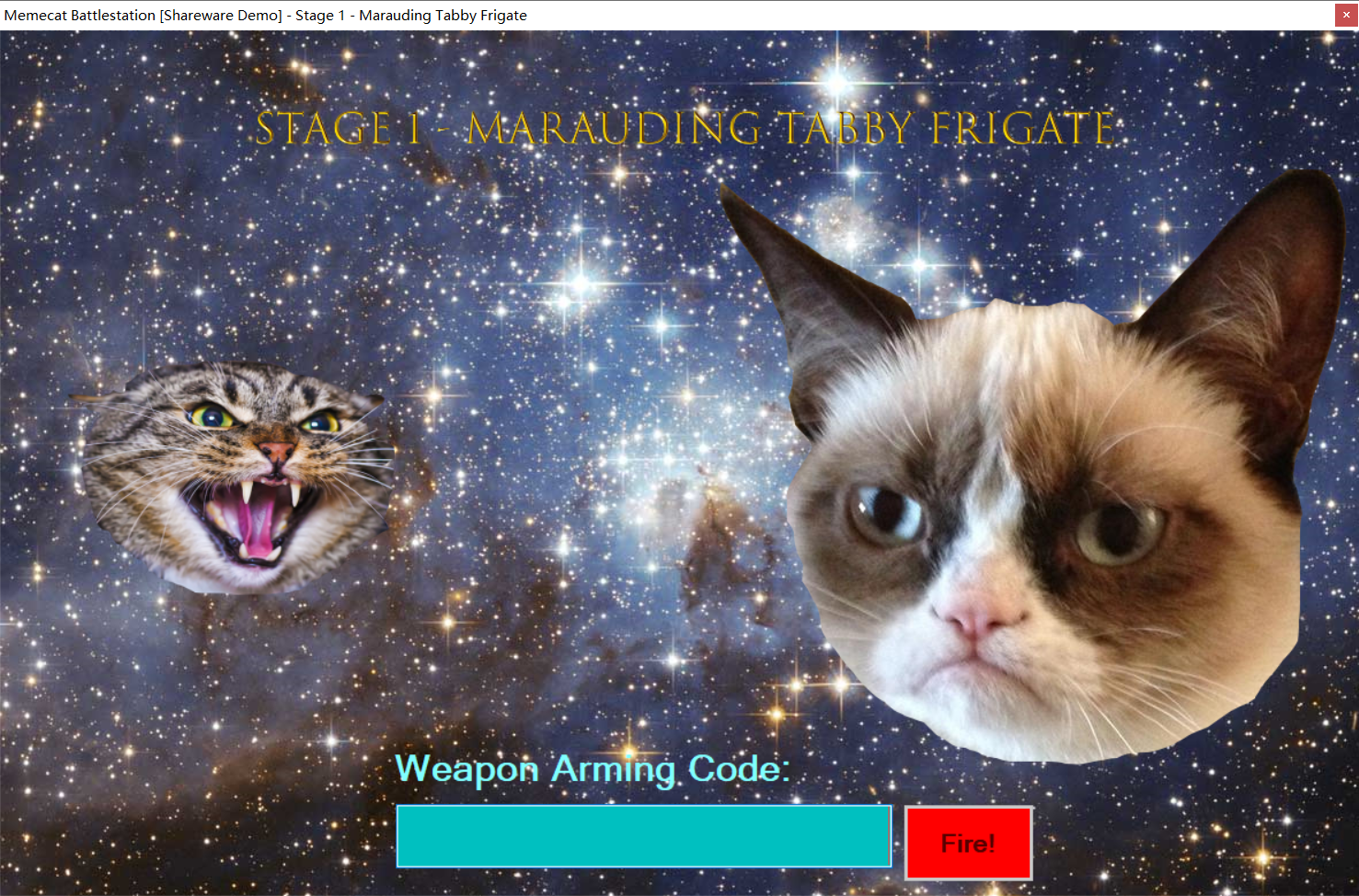
发现让我们输入code,我们用dnspy分析
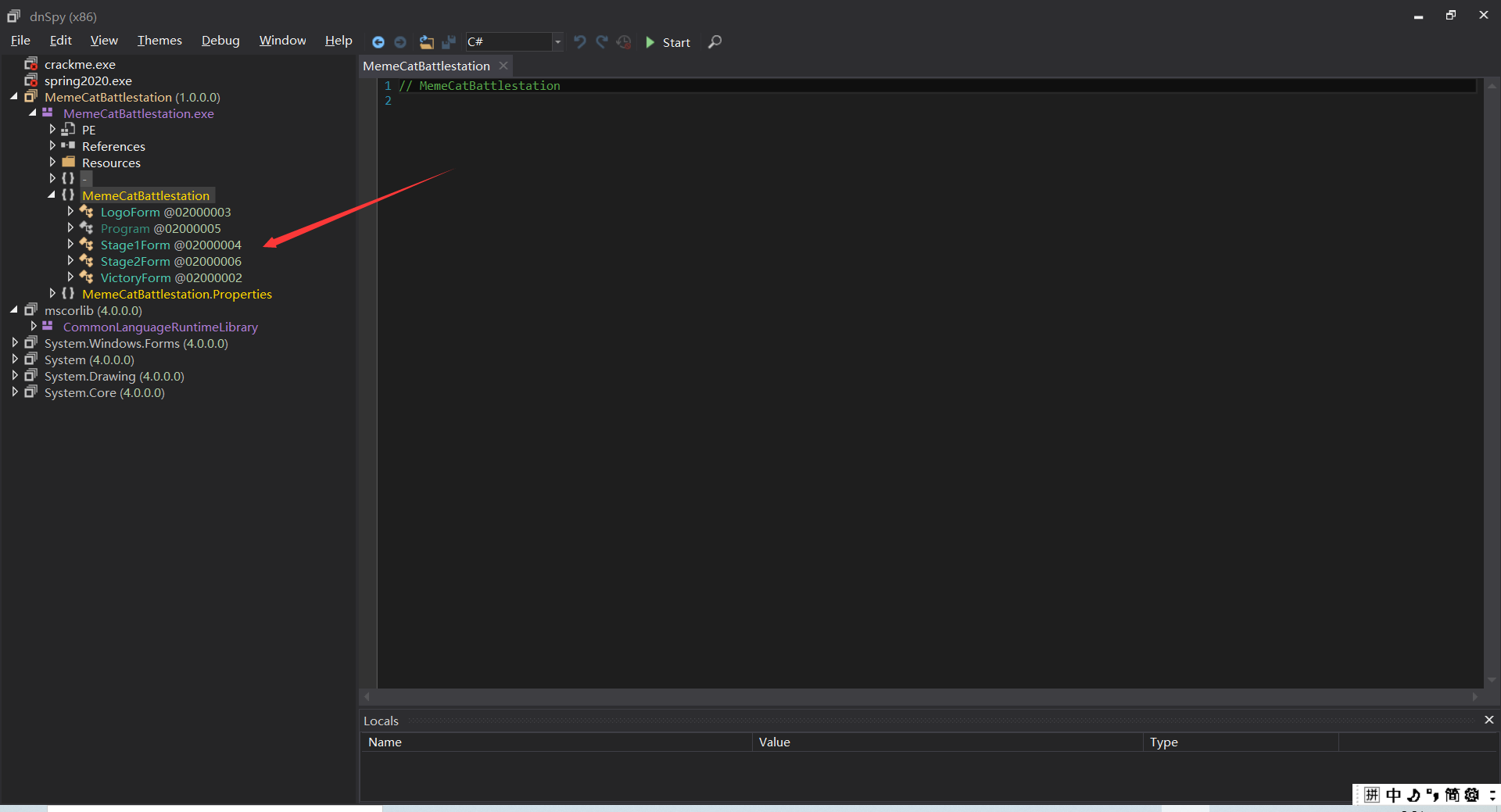
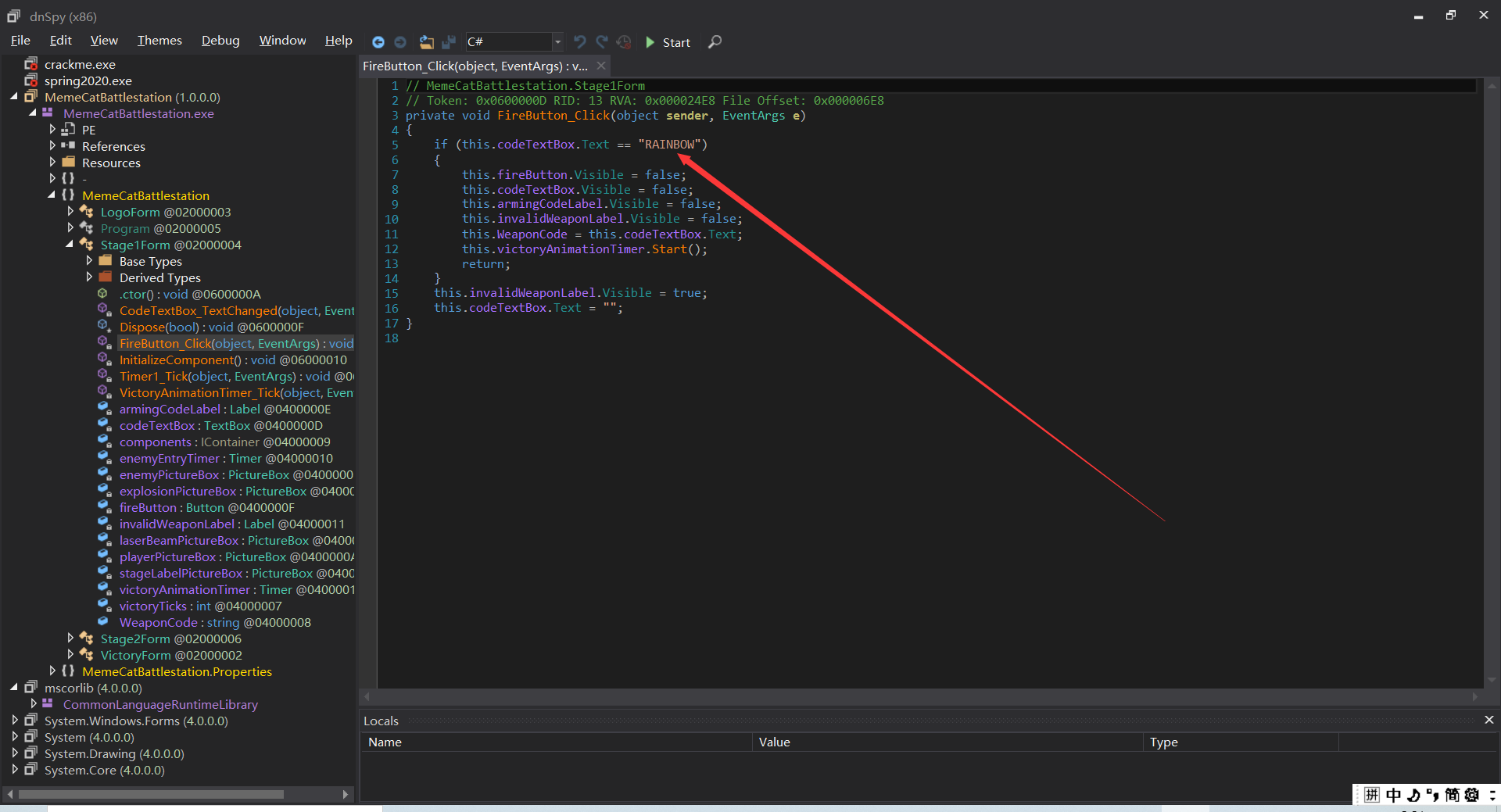
发现了第一个字符串RAINBOW
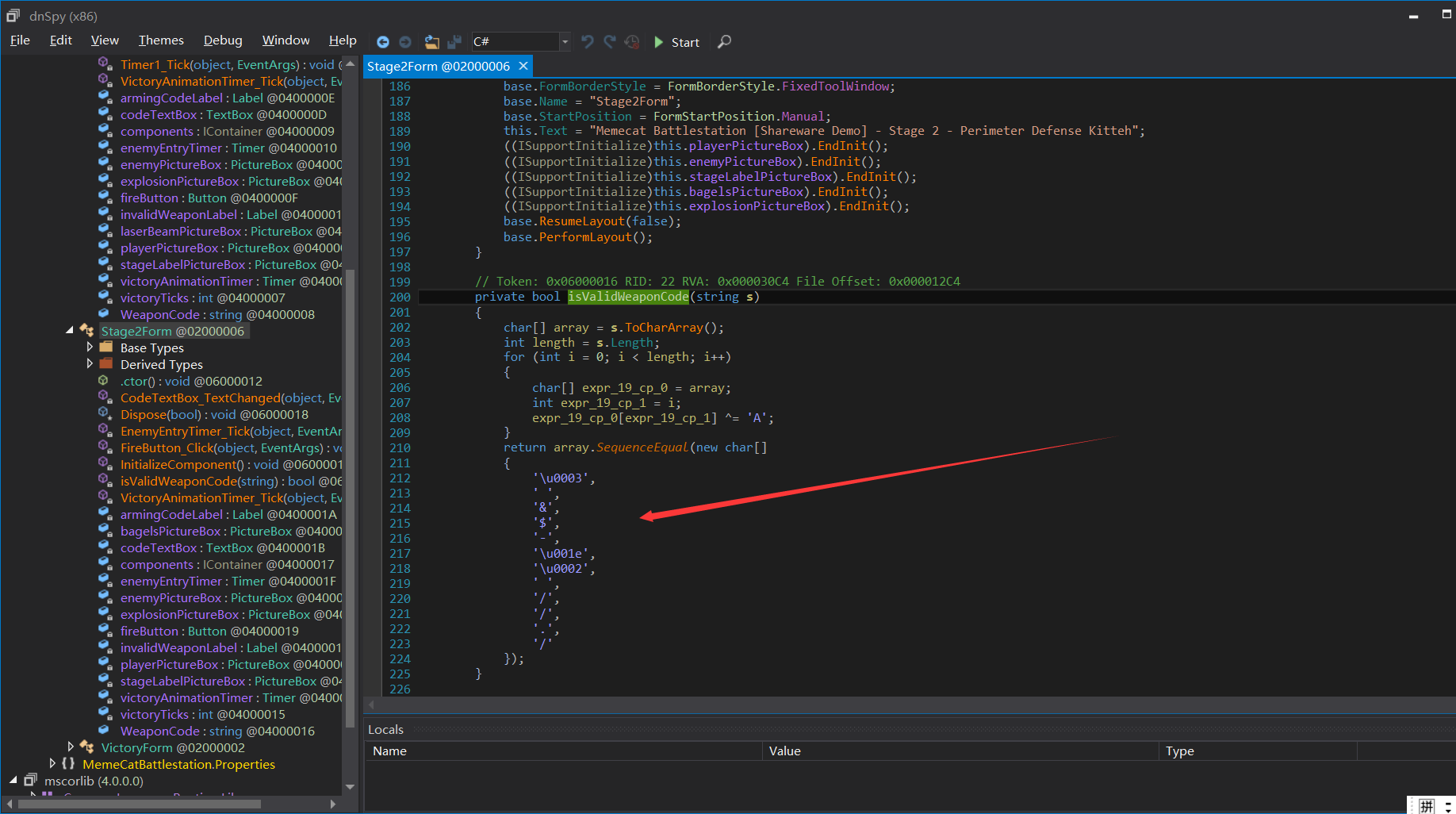
第二个我们发现了与A进行一个异或
1 | #include<stdio.h> |

flag:Kitteh_save_galixy@flare-on.com
👴做了个flare-on最简单的题放松一下 嘿嘿!准备看会动漫睡觉觉了
4.23日更新
👴今天又是2点多起的床,贼蒙!👍 起床赶紧学习吧!为了晚上可以玩玩生化危机3重制版 😘
步入正题!
多维数组
存放相同类型的数据的时候会用到数组,存放的地址是低地址到高地址来排序的
1 | int arr[6]={0,1,2,3,4,5} |
👌这个例子应该就懂了,低地址到高地址这样的,没毛病
假设数组没满怎么办,看一下
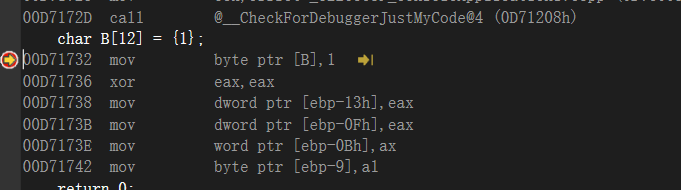
看到了,会异或eax,然后把eax给数组剩下的空间,数量不够,自动补上0,数组在引用的时候,可以里面写成变量
如果数组下标越界,他虽然不在数组里但是一定在堆栈里,测试一下
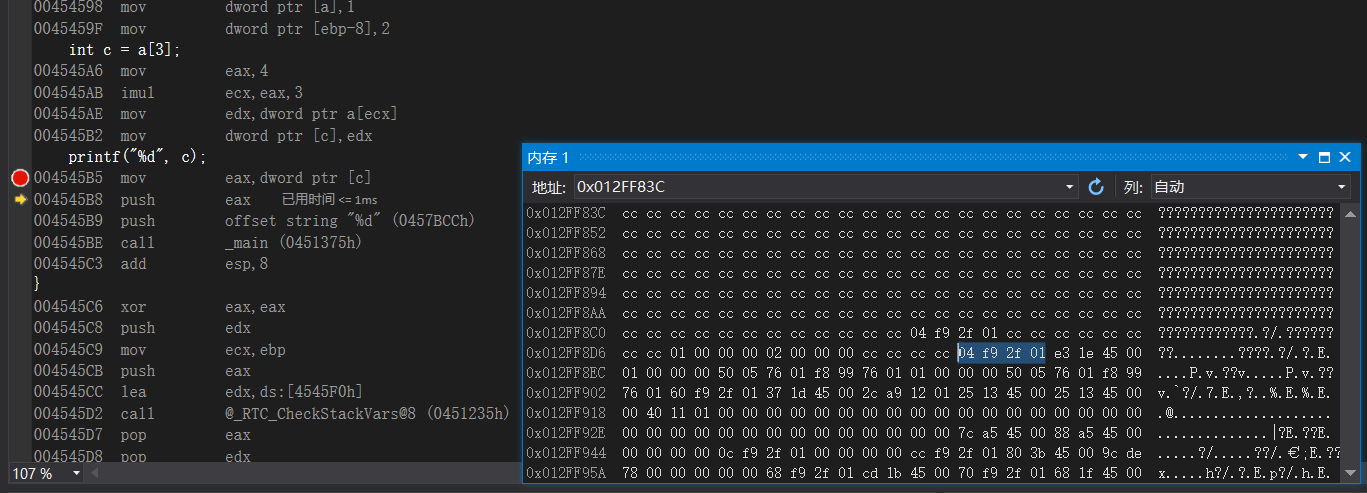

直接举个例子,👴懂了,这里注意一下每个编译器的规则都是不同的
这里跟说一下,当初遗留的问题:缓冲区溢出的时候,int a = (int)helloword这里的helloword是一个函数名,上面有,那么在这个程序里,他也相当于一个全局变量,我们打印出来就是这个程序中他的地址,本质上和全局变量没有什么区别,所以这么说来根据上面的溢出的试验,就可以很好的去说明,为什么vs中用这个不好使,因为溢出的时候,他给的是ebp-0x4的当前的地址,那么就会出现大问题,ebp-0x4是局部变量,所以就会失败,在vc6.0中,是改变了ebp+0x4的地址所以美欧问题
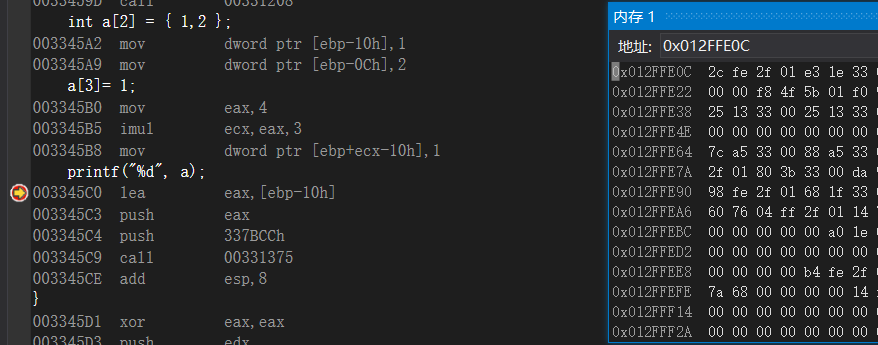
举这个例子就该懂了(👴为了让自己看的清楚一些,把那个地址都搞了出来看,这样就无敌了)
总结:假设数组为a[5] 那么我取a[5]的时候为ebp+0x4,a[6]为ebp,a[7] 为ebp-0x4,vs预留了一字节的空间

👴搞明白了
二维数组
直接去观察反汇编
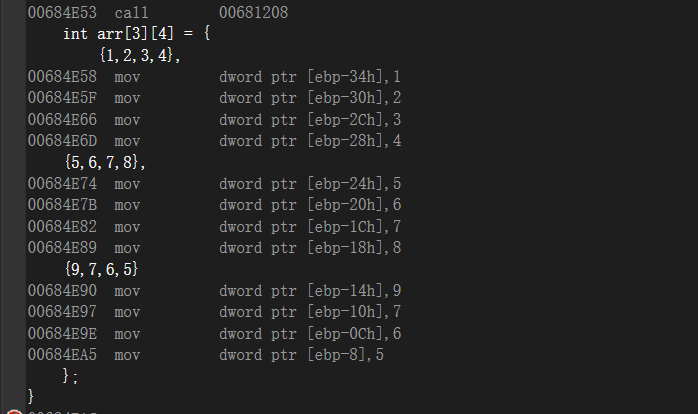
好像和一维数组的反汇编差不多,测试了一下,他们是一摸一样的,啥区别没有,不管一维数组还是多维的数组,实际上反汇编上没有区别 实际上a[x][y]相当于了a[x*y]分配x*y的空间
二维数组,更加直观,假设我要是找一下a[q][p]编译器寻找的时候是满足 a[q*x+p*y]二维数组打印的时候,用的是两层循环
👴看了一下,后面海哥讲的就是三维数组了,三维数组和两维数组类似,无非就是多了一组大括号,反正再底层来说n维数组就等同于一维数组,只是方便于我们观看而已,👴吃完饭,准备看小黄书了
开始小黄书:
各类型指针的工作方式
今天鸽一天小黄书,身体扛不住了,很难受😭明天补回来!
4.24日更新
👴今天7点就起床了,但是我磨蹭了一会,到了9.15才开始学习,今天任务先是小黄书把昨天的那份也补回来,然后看滴水逆向,🏃♂️去拿书开始看
步入正题!
开始小黄书:
各类型指针的工作方式
指针保存的都是地址,每种数据类型在内存中所占的内存空间不同,指针中只保存了存放数据的首地址,没有指明在哪里结束,所以需要根据对应的类型来寻找解释数据的结束地址,同一个地址使用不同类型指针进行访问,取出的内容就会不一样
各类指针访问同一地址代码
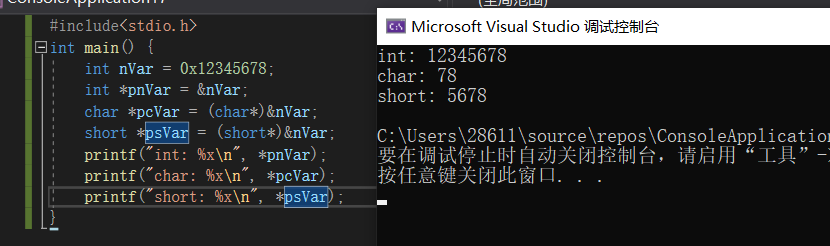
1 | //c++源码对比,定义int类型变量,初始化为0x12345678 |
👴这里要去vs测试一下,看看我自己对源码的分析对不对,我分析的就是,取出来的地址会根据指针类型的长读来取出来
这里测试没有问题的,我们去反汇编看一下,🏃♂️gogo!
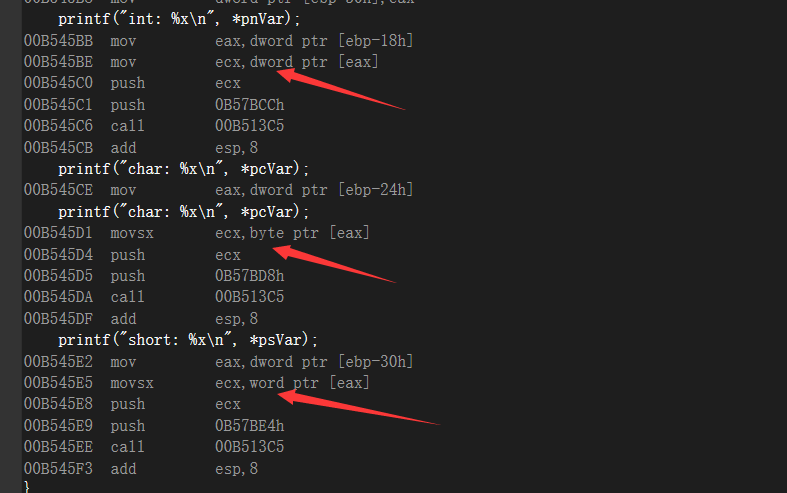
看了一下反汇编,和源码解析的差不多,反汇编的意思大概差不多,差别就是编译器的不同,👍只要有汇编,他编译器干什么就都会知道了
总结:在我存入的是0x12345678的时候再内存中存放是根据小端序存放78 56 34 12,首地址从7 8 开始,指针pnVar为int类型指针,以int类型在内存中占用的空间大小和排列的方式对地址进行解释,然后取出数据,int占4字节,所以取出来12345678,我们知道如上图所示,大地址到小地址会进行截取,eax本身就是4字节的空间,那么我分给word和byte的时候,会把前面的低地址位置进行一个截取,取高地址的位置,所以说会把前面的数据砍掉,然后用movsx进行分析符号位的填充
所有类型的指针对地址的解释都取决于自己本身的指针类型,指针做加法和减法比较有意义,因为指针是保存和解析地址而存在的,我们对指针的地址偏移时,偏移会根据自身的指针类型来决定
各类型指针寻址方式代码
1 | //c++源码对比,定义字符型数组,占5字节内存空间 |
总结:编译量的计算方式为指针类型长度乘以移动次数,因此得出指针寻址公式如下
$$
(p+n)目标地址 = 首地址 + sizeof(指针类型)*n (n为移动次数)
$$
两指针做减法,可以求出两地址之间的元素个数(必须同类指针相减),两指针相加没有作用,公式如下
$$
p-q = ((int)p - (int)q) / sizeof(指针类型)
$$
引用
引用类型在c++中被描述为变量的别名,c++为了简化指针的操作,对指针的操作进行了封装,产生了引用类型,实际上引用类型就是指针类型,只不过它用于存放地址的内存空间对使用者而言是隐藏的
引用类型代码
1 | //c++源码对比,定义int类型的变量并附初始值0x12345678 |
引用类型的存储方式和指针是一样的,都是使用内存空间存访地址值,所以在C++中,引用和指针没有区别,引用时通过编译器实现寻址,而指针需要手动寻址,所以说如果操作失误会有比较糟糕的结果,但是引用就不会存在这种问题,所以c++很推荐使用引用类型,并不是指针
引用类型作为函数参数代码
1 | void Add(int &nVar){ |
这里我看到的结论就是引用的时候,并没有像指针一样进行了数据类型的那种的移动,而就是单纯的进行了数据+1,我们测试一下
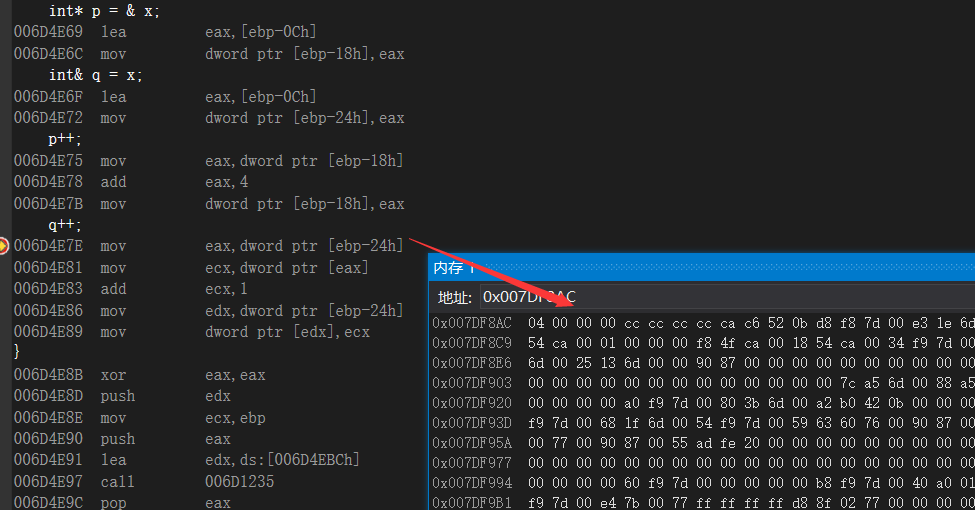
因为前面有一个lea的操作把地址给了eax,然后eax给了ebp-0x24,所以引用也相当于取别名
常量
常量数据在程序运行前就已经存在,他们被编译到可执行文件中,当程序启动后,他们会加载进来,数据通常会在常量数据区中保存,该节区的属性没有写权限,所以不可以修改
常量数据的地址减去基质就是文件中的编译地址

常量的定义
C++中,使用#define来定义常量,也可以使用const将变量定义为一个常量,#define定义的常量名称,编译器对其进行编译时,会将代码中的宏名称替换成对应信息,宏的使用可以增加代码的可读性,const是为了增加程序的健壮性而参在的,常用字符串处理函数stcpy的第二个参数被定义为一个常量,为了防止该参数在函数内被修改,对原字符串造成破坏
宏与const的使用
1 | //定义NUMBER_ONE 为常量1 |

#define和const的区别
#define是一个真常量,而const却是由编译器判断实现的常量,是一个假常量,实际中使用const,最终还是一个变量,只是在编译器内进行了检查,发现有修改则报错
由于编译器在编译期间对const变量进行检查,因此被const修饰过的变量是可以修改的,利用指针获取到const修饰过的变量地址,强制将指针的const修饰去掉,就可以修改对应的数据内容
1 | //c++源码对比,将变量nConst修饰为const |
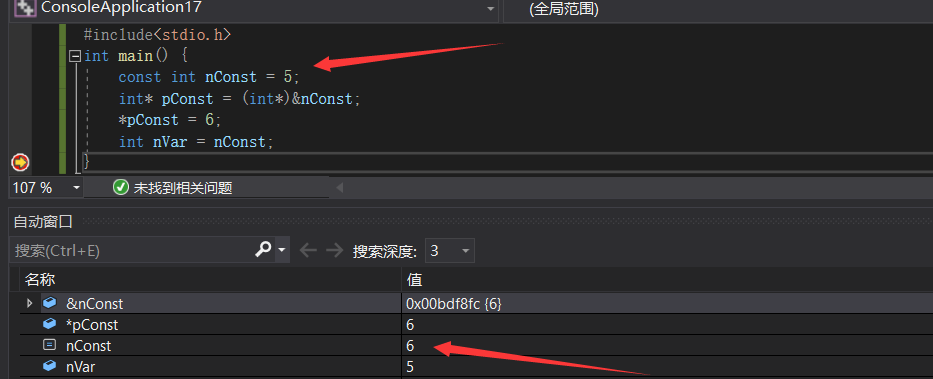
所以说const修饰的变量nConst被赋值了一个常量5,编译过程中发现nConst的初值是可知的,并修饰为const,之后所有使用的nConst的位置都用这个可预知值替换,所以最后nVar替换的是预知的常量值5,如果nConst是未知的值就不会进行这个优化
#define与const两者的区别
| #define | const |
|---|---|
| 编译期间查找替换 | 编译期间检查const修饰的变量是否被修改 |
| 由系统判断是否修改 | 由编译器限制修改 |
| 字符串定义在文件只读数据区,数据常量编译为立即数寻址方式,成为二进制代码的一部分 | 根据作用域决定所在的内存位置和属性 |
👴昨天的补完了,开始今天的美滋滋的小生活,🏃♂️趁热打铁,去继续看小黄书7777777777777777
继续小黄书:
程序入口
一般VC++调试的程序,一般都是在main或者WinMain函数开始的,所以说很多人包括👴很久之前就认为他们是程序的第一条指令处,这个是不对的,main或者是WinMain来说是一个函数,也是需要被调用的,他们没有被调用之前,编译器做了很多的事情,所以main和WinMain来说是语法规定的用户入口,并不是应用程序的入口,其实我们的程序被操作系统加载的时候,操作系统会分析执行文件内的数据
4.25日更新
最近这两天爷有点小忙,呜呜呜😭学校作业都没做,在狂补,然后最近身体不太好,经常学一会就休息,坐不住,今天尽量完成计划任务!
任务:滴水逆向+小黄书+安恒月赛(1.30开始)
步入正题!
结构体
类型从小到大:char short int float double _int64 数组
数组的问题:类型必须一样
结构体里面想存什么类型就存什么类型
1 | struct AA{ |
开始小黄书:
👴接着昨天的说,最近要出题那些,搞的静不下心来看书,小黄书看完,我就去把c++看一手
程序入口
昨天说到了,main或者WinMain是语法规定的用户入口,而不是应用程序入口,在应用程序被操作系统加载的时候,操作系统会分析执行文件内的数据,分配相关的资源,读取执行文件中的代码和数据到合适的内存单元,然后才是执行入口代码,入口代码通常是mainCRTStartup,wmianCRTStartup,WinMainCRTStartup或wWinMainCRTStartup,具体的要根据编译选项来定夺,其中mainCRTStartup和wmainCRTStartup是控制台环境下多字节编码和Unicode编码的启动函数,而WinMainCRTStartup和wWinMainCRTStartup是Windows环境下多字节编码和Unicode编码的启动函数,vc++也可以让自己去指定入口
VC++ 6.0启动函数
VC++6.0 控制台和多字节编码环境下的启动函数mainCRTStartup,由系统库KERNEL32.dll负责调用
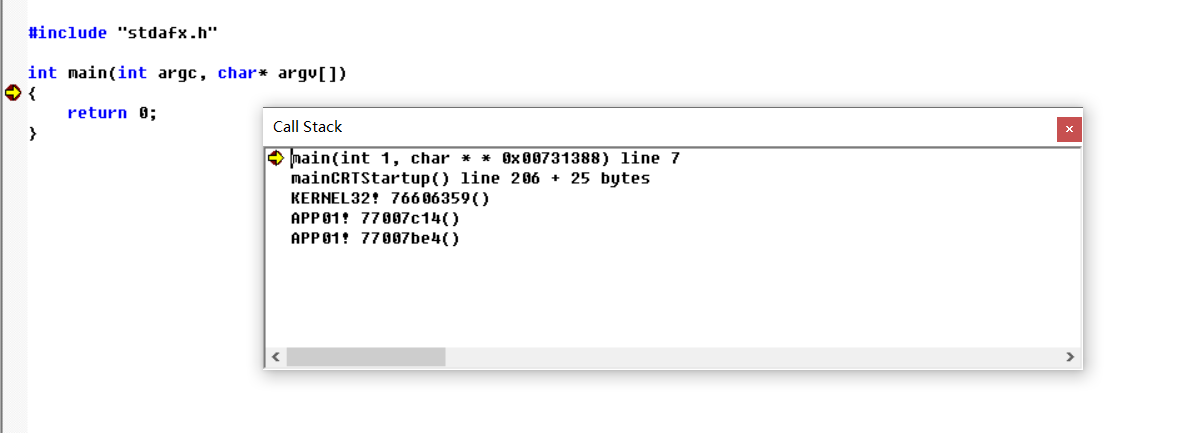
👴去安装了个vc++ 6.0 可以看到程序运行时调用了三个函数,KERNEL32.dll,mainCRTStartup和main
其中KERNEL32!76606359()表示在76606359地址调用了mainCRTStartup,VC++提供了mainCRTStartup的源码,直接过去看一下,分析一下(自己没有安装完整版的,导致看不到,直接用书上的一点一点分析了)
mainCRTStartup函数代码片段
1 | //预编译宏 |


